2024. 2. 13. 19:52ㆍSKKU DT
웹 스크래핑(크롤링)
-웹사이트에서 원하는 정보를 자동으로 수집하고 정리하는 것. 반복적인 작업을 자동화 할 수 있다.
-가격 비교, 검색 엔진, 소셜 미디어 분석(# 태그), 인스타 여러 계정의 새로운 게시물이 생길 때 마다 내가 만든 계정에 업로드 되게 할 수 있다.
원하는 데이터를 수집
수집한 정보를 알맞게 가공

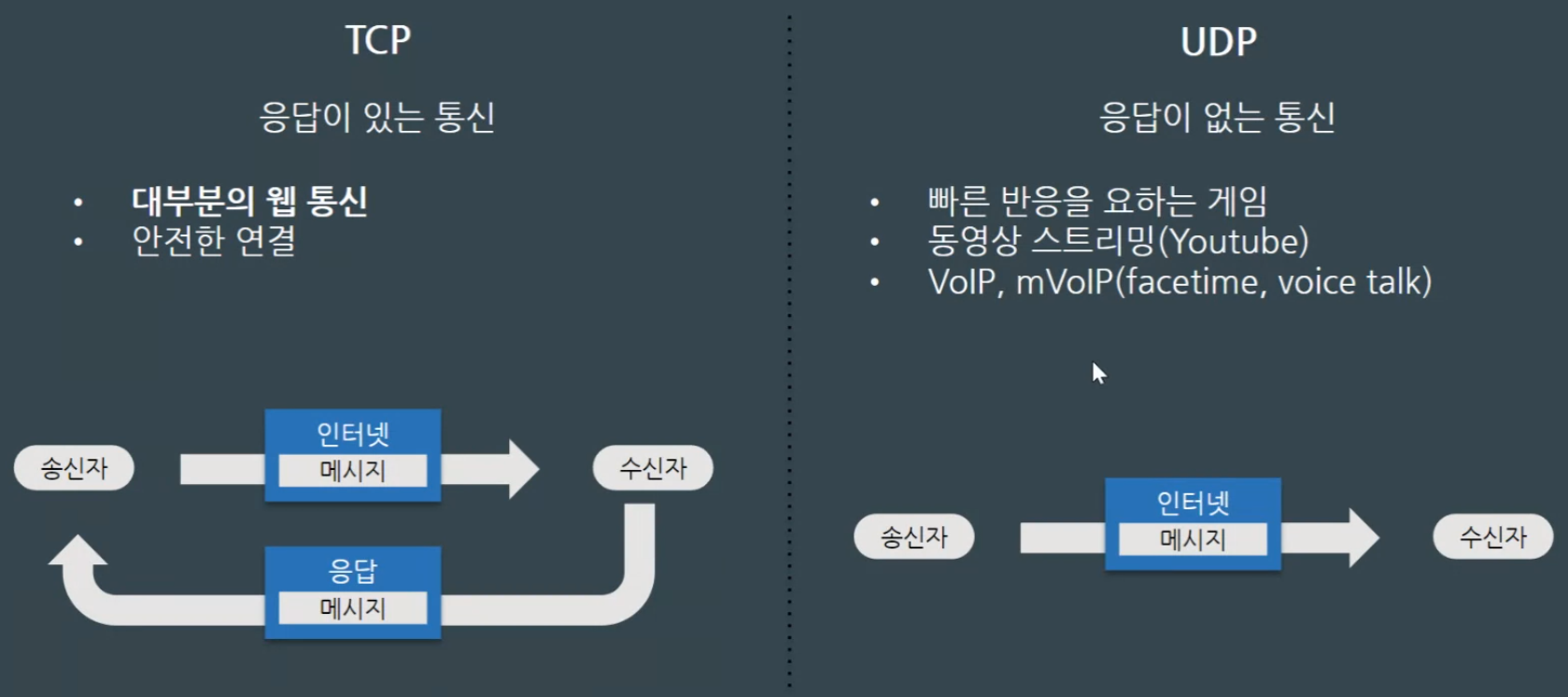
TCP 통신
-응답이 있는 통신(대부분의 웹 통신)
-API도 TCP 통신이다.
-서로 명함을 주고 받는 느낌
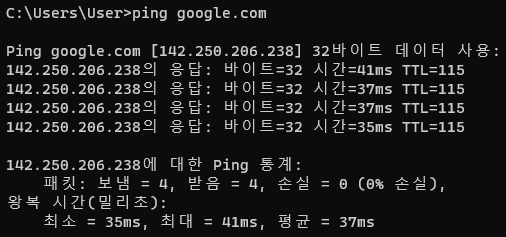
ping 통신은 icmp 통신규약으로, ping google.com을 cmd 창에 입력하는 것 만으로도 응답시간을 볼 수 있다.
UDP 통신
-빠른 반응을 요하는 게임(게임이 렉걸리면 갑자기 몬스터에 둘러싸이는 현상이 생길 수 있다.)
-동영상 스트리밍
-Facetime, Discord
-받는 사람이 있던 말던 길거리에 명함을 뿌리는 느낌
웹 통신

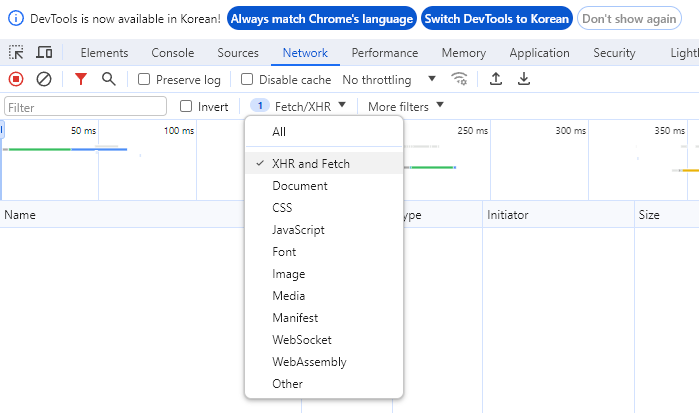
F12 눌러서 나오는 개발자툴에서, [Network] 탭 중 XHR 필터를 걸면, 자동 저장처럼 웹페이지를 새로고침 하지 않아도 변경된 사항을 볼 수 있다.
HTTP 메소드
-GET, POST, PUT, DELETE 대표적으로는 네 가지가 있다. 아래 링크에서 더 찾아볼 수 있다.
https://developer.mozilla.org/ko/docs/Web/HTTP/Methods
HTTP 요청 메서드 - HTTP | MDN
HTTP는 요청 메서드를 정의하여, 주어진 리소스에 수행하길 원하는 행동을 나타냅니다. 간혹 요청 메서드를 "HTTP 동사"라고 부르기도 합니다. 각각의 메서드는 서로 다른 의미를 구현하지만, 일부
developer.mozilla.org

(*부분만 수정할 때는 PATCH, 통째로 수정할 때는 PUT을 쓴다.)
Response의 응답 코드

데이터 포맷 형식
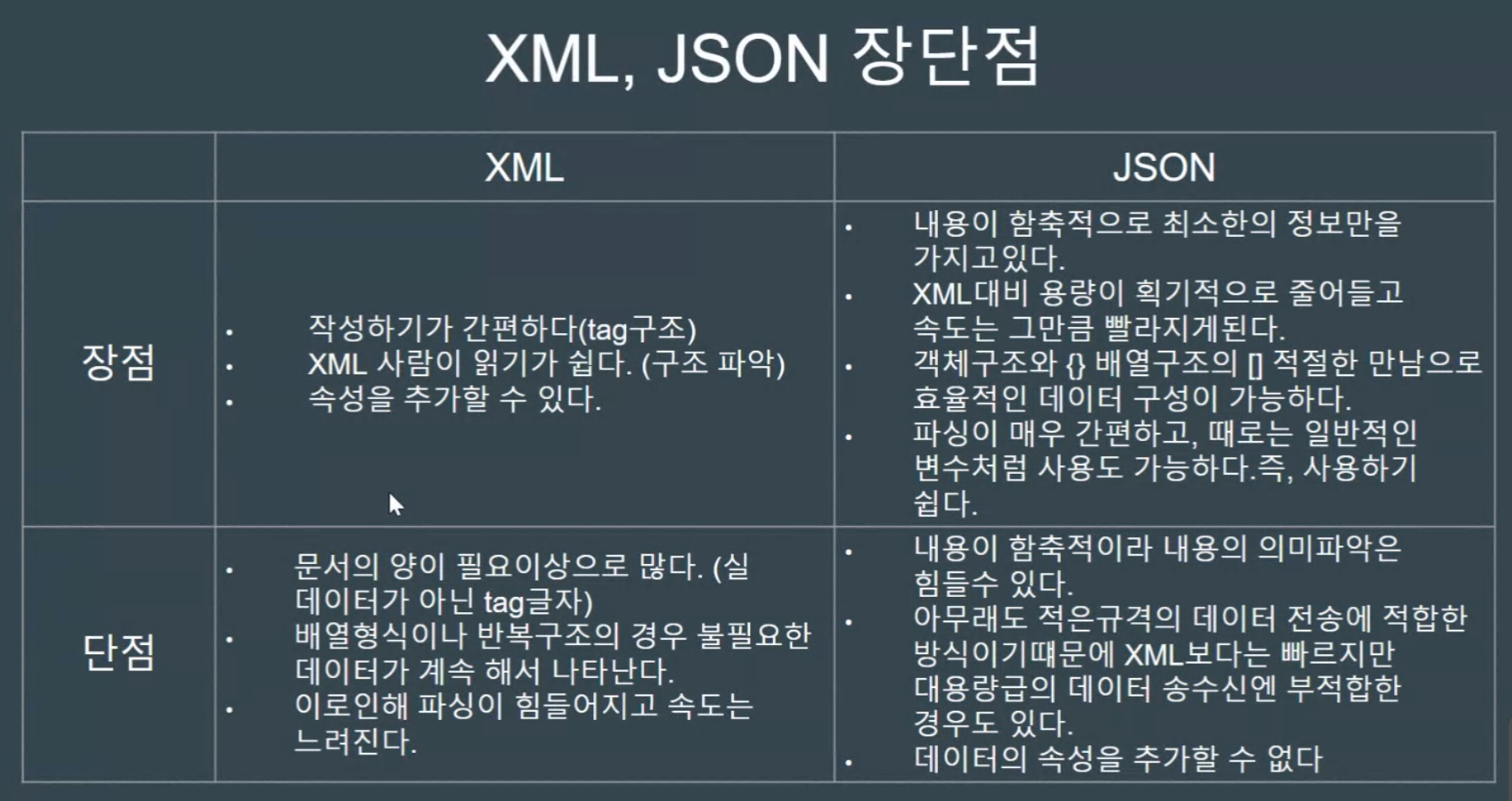
-XML과 JSON이 있다.
-Json은 Python Dictionary와 비슷하지만 다르다. Python에서는 json을 load해서 Dictionary로 변환하는 내장 Library가 있다.

XML과 JSON의 장단점
Requests 예제 작성
아래는 Request 라이브러리 공식 사이트와 Github이다.
https://requests.readthedocs.io/en/latest/
Requests: HTTP for Humans™ — Requests 2.31.0 documentation
Requests: HTTP for Humans™ Release v2.31.0. (Installation) Requests is an elegant and simple HTTP library for Python, built for human beings. Behold, the power of Requests: >>> r = requests.get('https://api.github.com/user', auth=('user', 'pass')) >>> r.
requests.readthedocs.io
https://github.com/psf/requests
GitHub - psf/requests: A simple, yet elegant, HTTP library.
A simple, yet elegant, HTTP library. Contribute to psf/requests development by creating an account on GitHub.
github.com
혹시 파이썬에서 import requests가 되지 않는다면, 아니면 다음과 같은 오류가 발생한다면,

[설정] - [고급 시스템 설정] - [고급 탭] - [환경 변수] - [사용자 변수] - [Path 편집] 에서 파이썬 설치 경로와 그 아래 Scripts 폴더 경로까지 추가하니 잘 진행되었다.
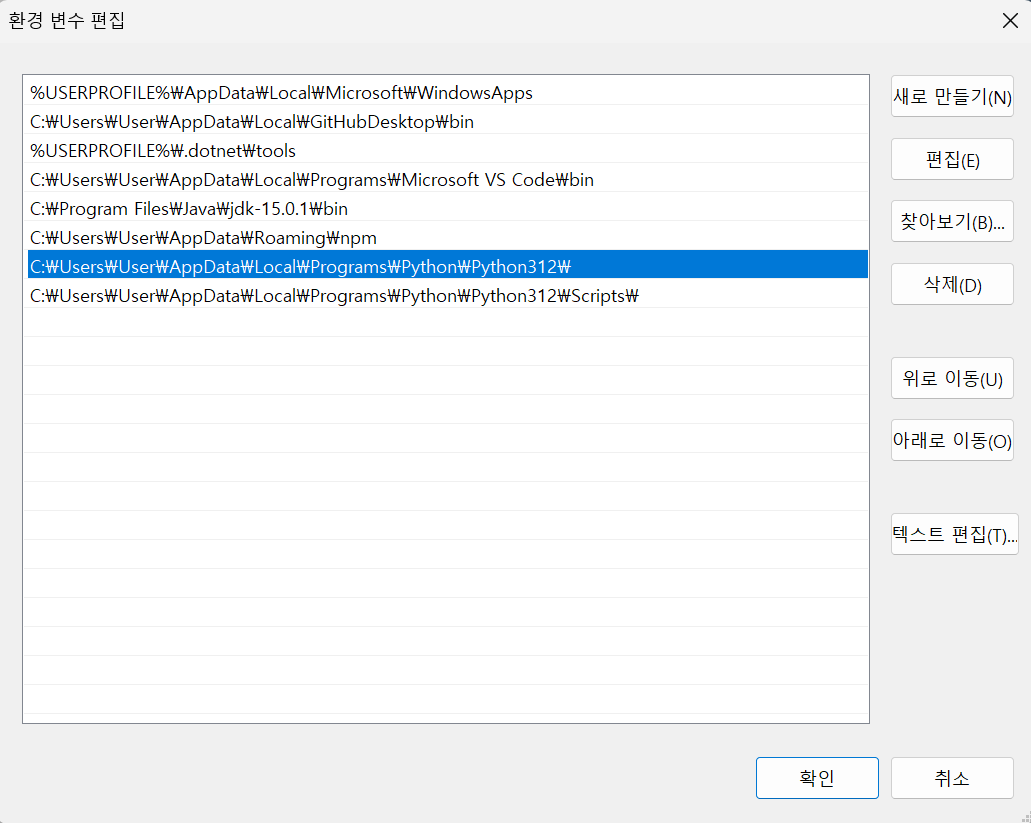
아래의 코드를 실행하면, 200 코드로 성공적으로 반응이 오는 것을 볼 수 있다.
import requests
response = requests.get("https://naver.com")
#response = requests.get('get', "https://naver.com")
#response = requests.post("https:/naver.com")
print(response)
response.text
import requests
response = requests.get("https://search.naver.com/search.naver", params={'query': '사이버트럭'})
print(response.text)
response.content
response.encoding

response.status_code

response.headers

response.url

BeautifulSoup
-HTML과 XML 파일로부터 데이터를 추출하기 위한 Python Library.
해당 라이브러리를 사용하기 위해 "pip install bs4"로 설치한다.
BeautifulSoup을 사용하여 어느 정도 정리가 된 출력을 볼 수 있다.
import requests
from bs4 import BeautifulSoup
response = requests.get("https://search.naver.com/search.naver", params={'query': '사이버트럭'})
soup = BeautifulSoup(response.content, 'html.parser')
print(soup.prettify())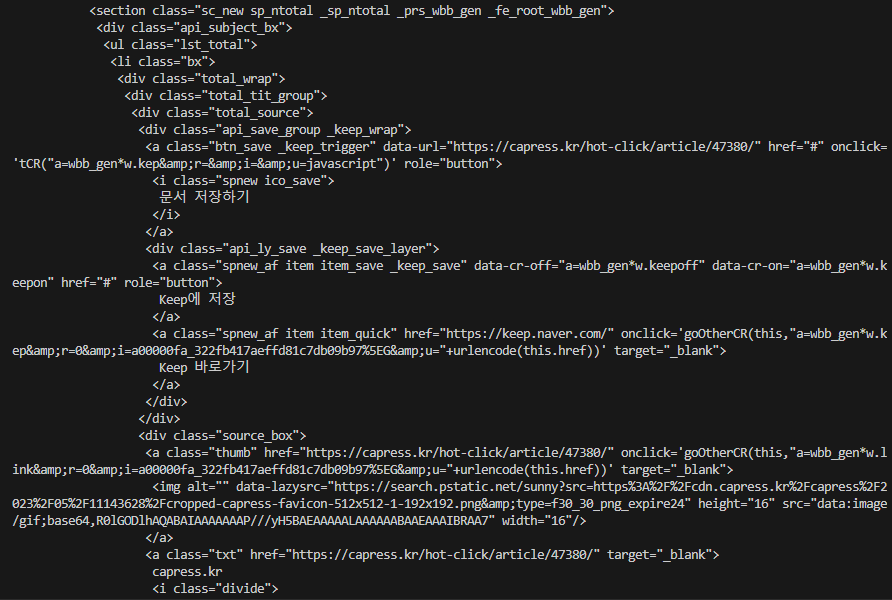
HTML Tags
- div : 영역을 잡아주는 태그
- ul / ol => li : 리스트를 가져올 수 있는 태그. 하위에 li 가 있다.
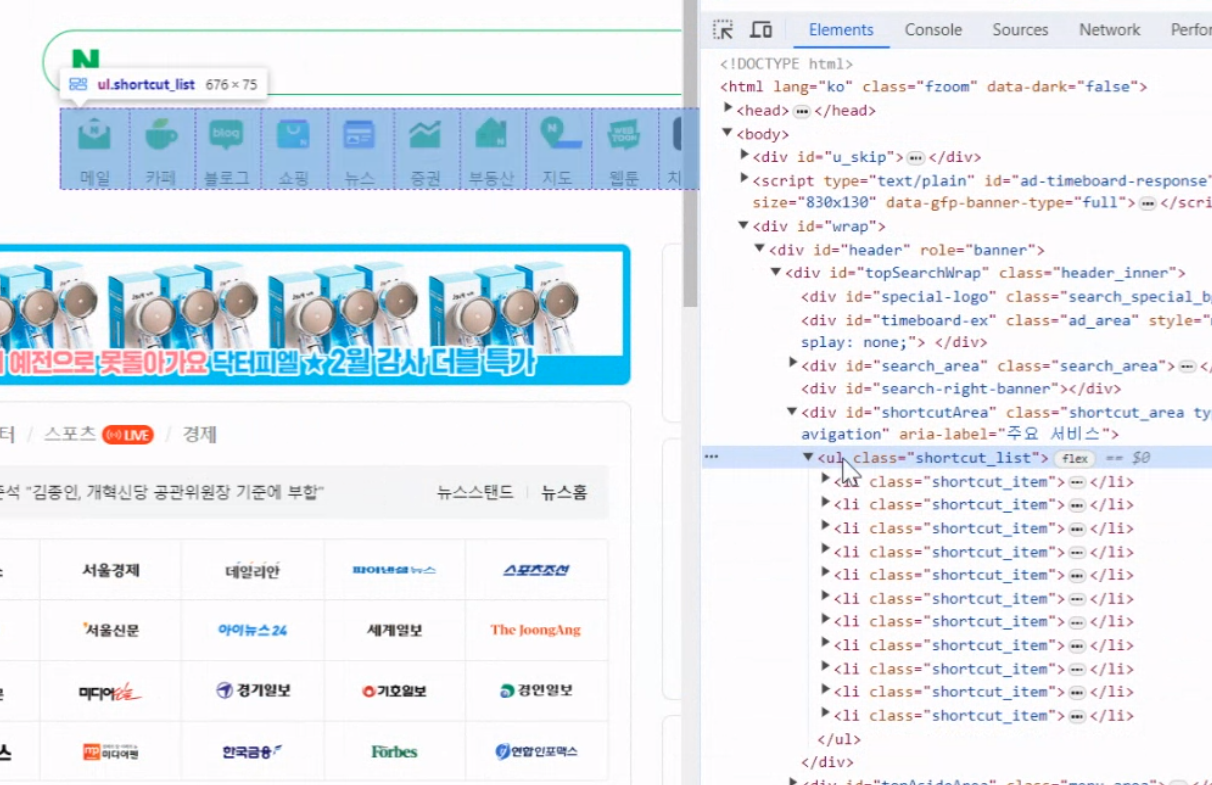
- a -> (href) : 하이퍼링크를 만들어주는 태그. href 속성을 찾으면 어떤 링크로 걸려있는 지 볼 수 있다.
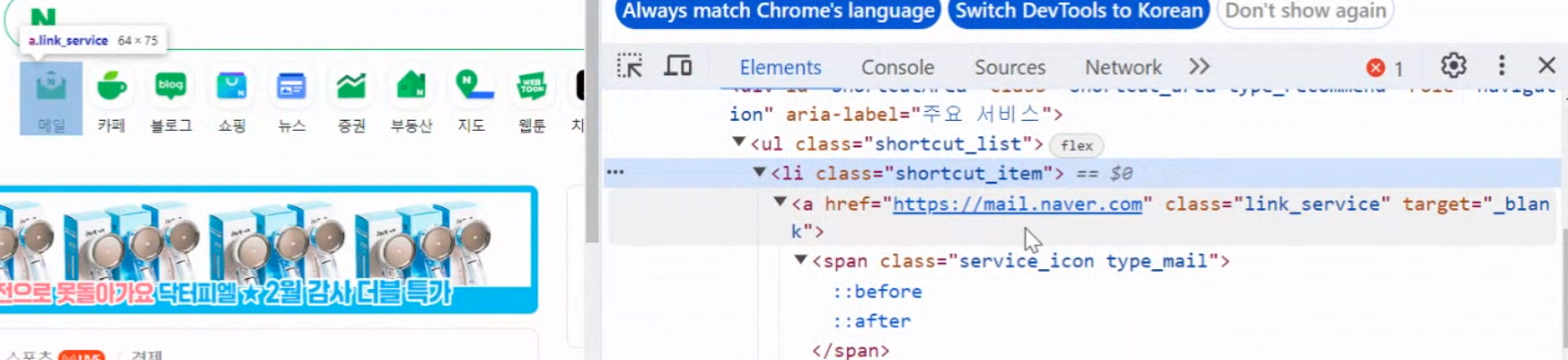
- img -> (src) : 이미지 태그. src 속성을 가져와서 이미지가 저장된 주소를 가져올 수 있다.
soup.img
import requests
from bs4 import BeautifulSoup
response = requests.get("https://search.naver.com/search.naver", params={'query': '사이버트럭'})
soup = BeautifulSoup(response.content, 'html.parser')
print(soup.img)
soup.img.attrs
json 형태로 출력
import requests
from bs4 import BeautifulSoup
response = requests.get("https://search.naver.com/search.naver", params={'query': '사이버트럭'})
soup = BeautifulSoup(response.content, 'html.parser')
print(soup.img.attrs)
src만 가져오기
import requests
from bs4 import BeautifulSoup
response = requests.get("https://search.naver.com/search.naver", params={'query': '사이버트럭'})
soup = BeautifulSoup(response.content, 'html.parser')
img = soup.img
print(img.get('src'))
find
가장 처음 하나만 찾기
import requests
from bs4 import BeautifulSoup
response = requests.get("https://search.naver.com/search.naver", params={'query': '사이버트럭'})
soup = BeautifulSoup(response.content, 'html.parser')
img = soup.find('img')
print(img)
find_all
배열로 가져온다.
import requests
from bs4 import BeautifulSoup
response = requests.get("https://search.naver.com/search.naver", params={'query': '사이버트럭'})
soup = BeautifulSoup(response.content, 'html.parser')
img = soup.find_all('img')
print(img)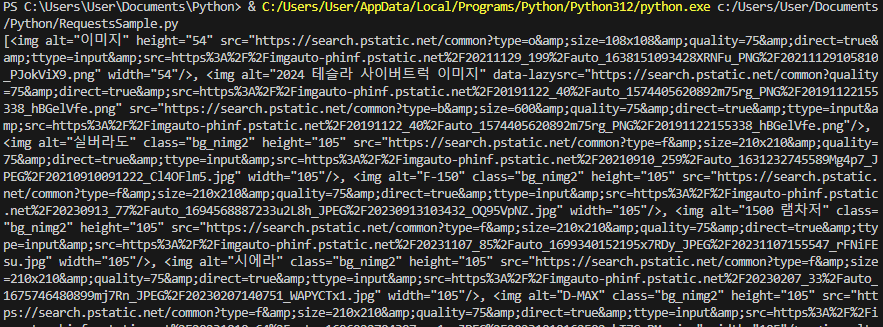
그 외
soup.descendants -자손들(generator)
import requests
from bs4 import BeautifulSoup
response = requests.get("https://search.naver.com/search.naver", params={'query': '사이버트럭'})
soup = BeautifulSoup(response.content, 'html.parser')
soup = soup.descendants
print(soup)
soup.parent -부모 태그
import requests
from bs4 import BeautifulSoup
response = requests.get("https://search.naver.com/search.naver", params={'query': '사이버트럭'})
soup = BeautifulSoup(response.content, 'html.parser')
soup = soup.div.parent
print(soup)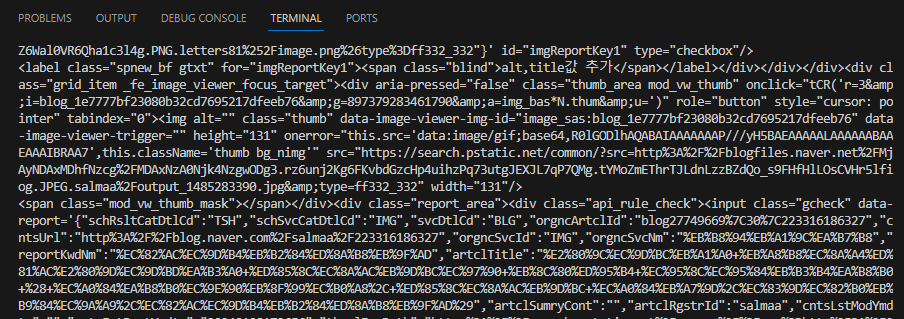
soup.parents -조상 태그(재귀적 호출)
soup.div.find_next_siblings() -형제 찾기
import requests
from bs4 import BeautifulSoup
response = requests.get("https://search.naver.com/search.naver", params={'query': '사이버트럭'})
soup = BeautifulSoup(response.content, 'html.parser')
div = soup.div
print(div.find_next_siblings())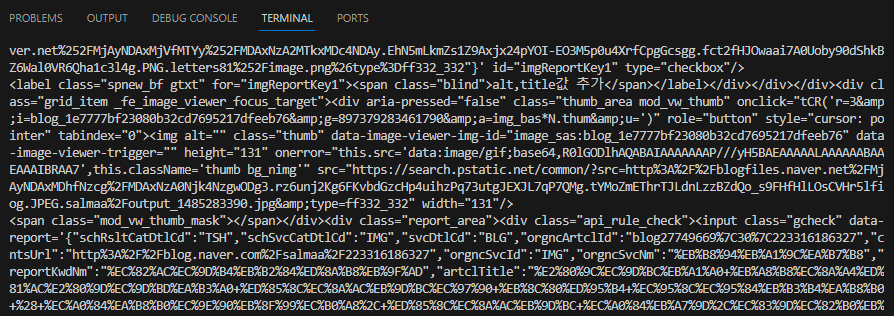
soup.div.find_previous_sibling() -이전 형제 찾기
import requests
from bs4 import BeautifulSoup
response = requests.get("https://search.naver.com/search.naver", params={'query': '사이버트럭'})
soup = BeautifulSoup(response.content, 'html.parser')
div = soup.div.find_next_sibling()
print(div.find_previous_sibling())
CSS Selector
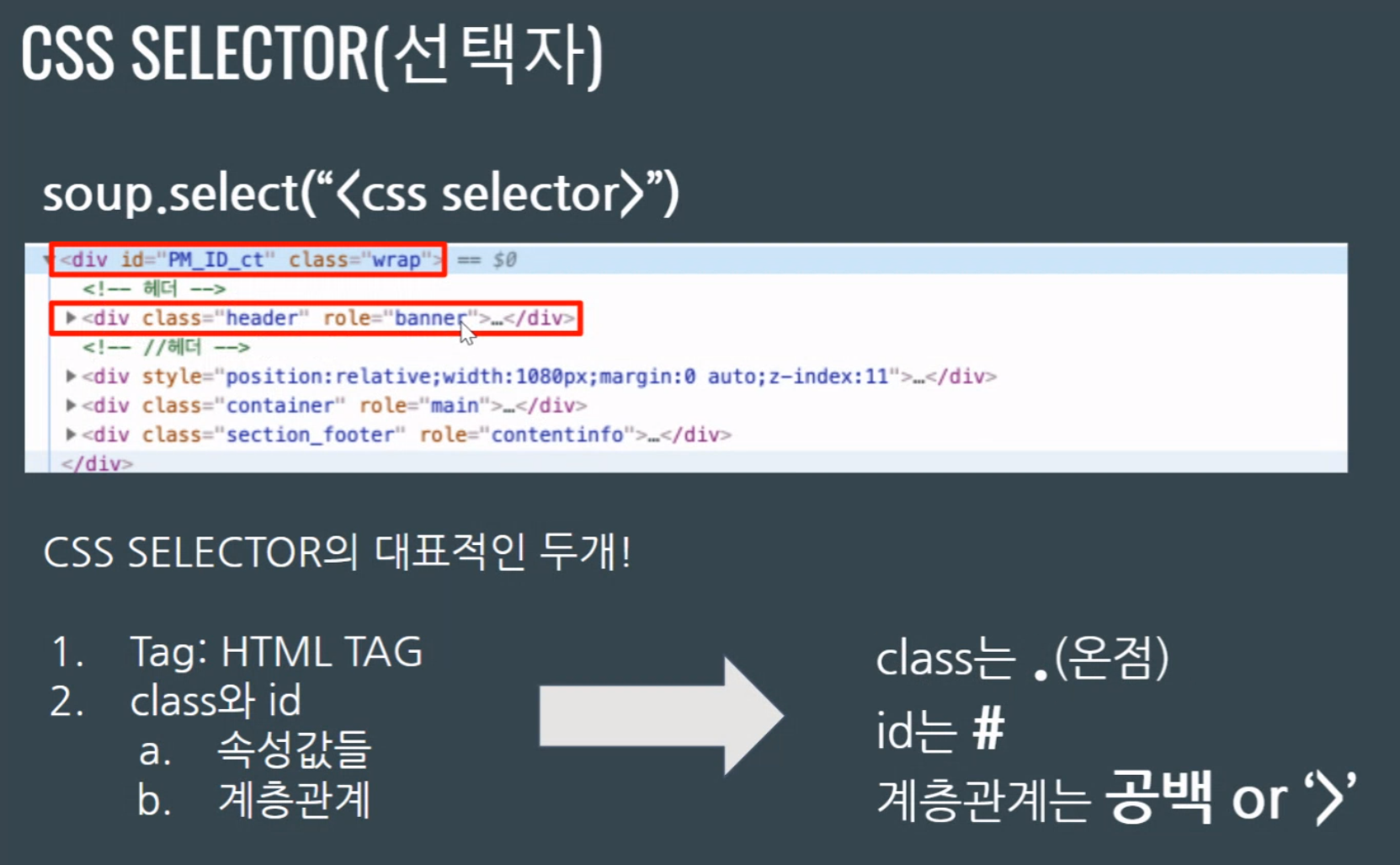
[Ctrl + F] 로 id 또는 Class를 검색할 수 있다.
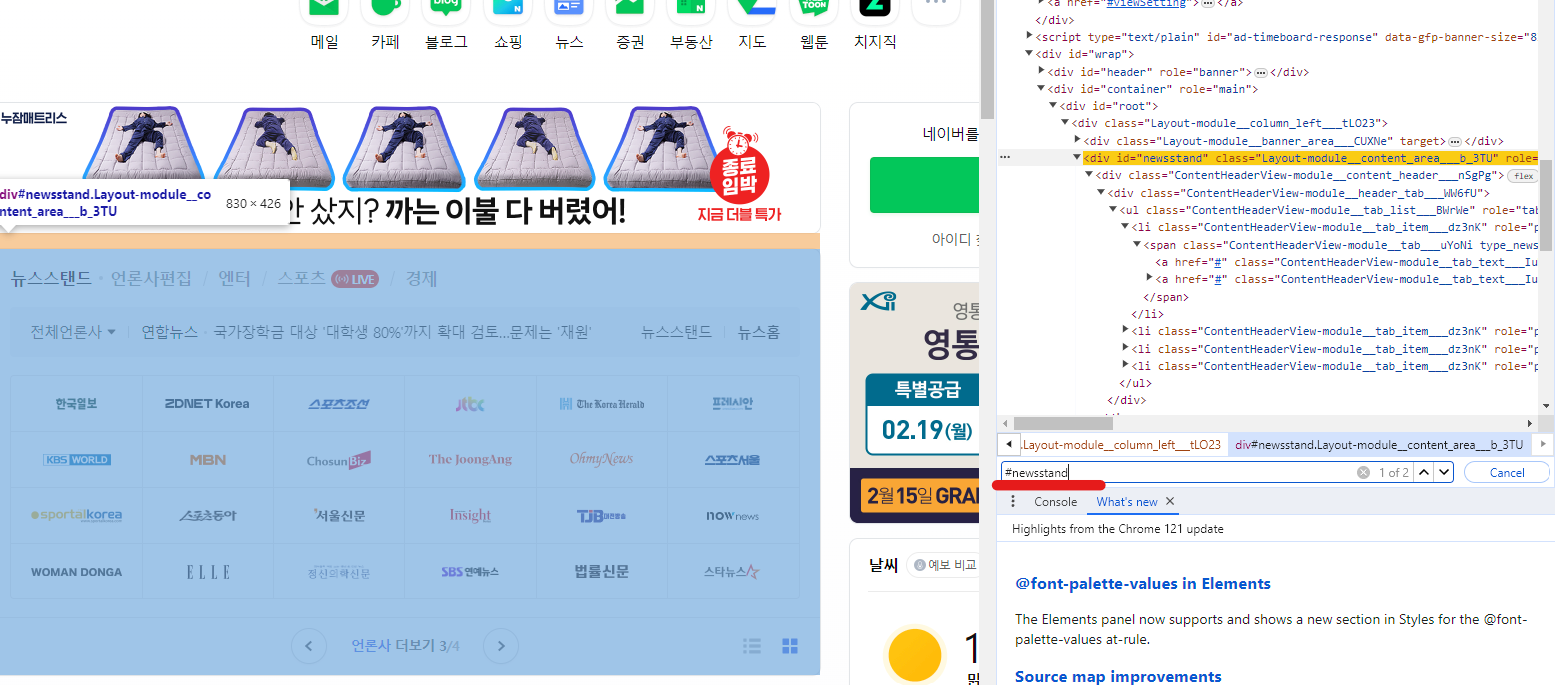
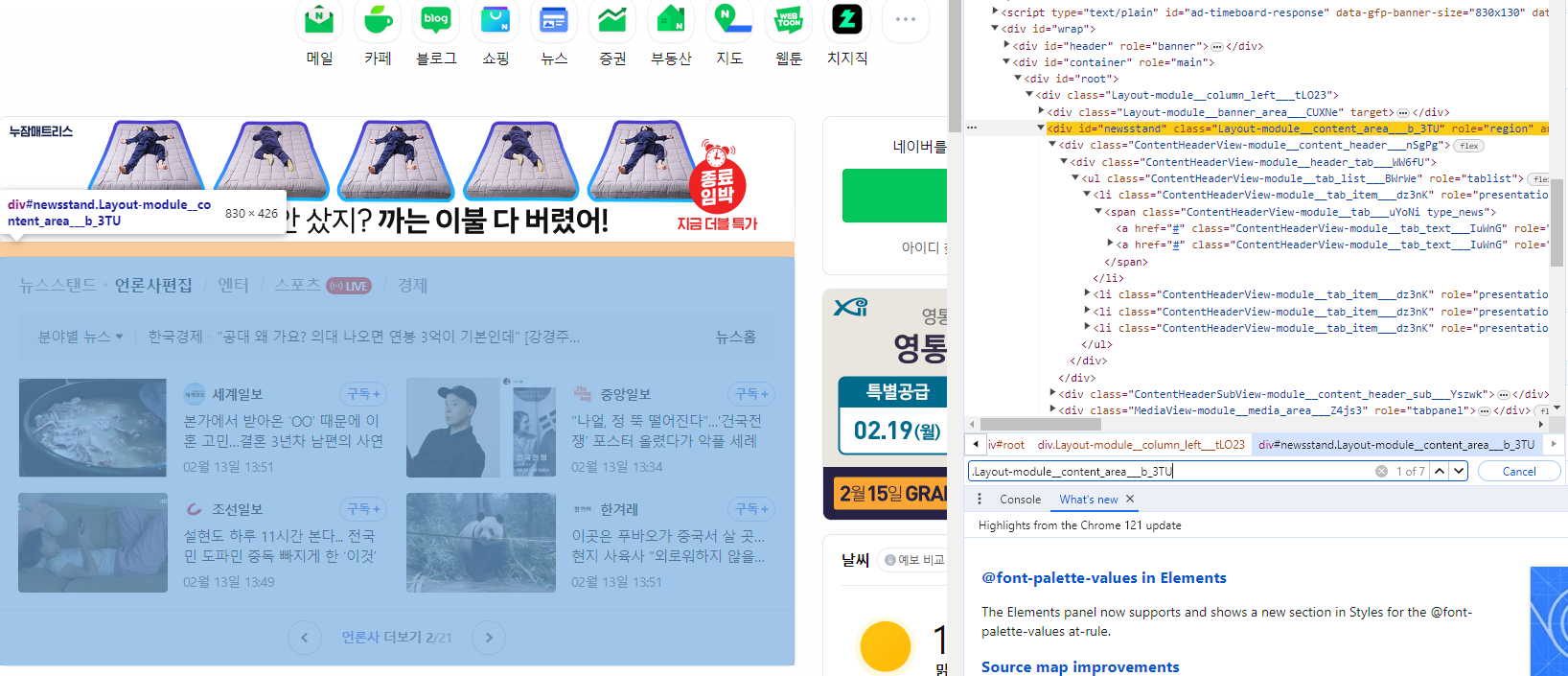
띄어쓰기 또는 꺾쇠로 부모 class 밑의 class를 직접 지정할 수도 있다.
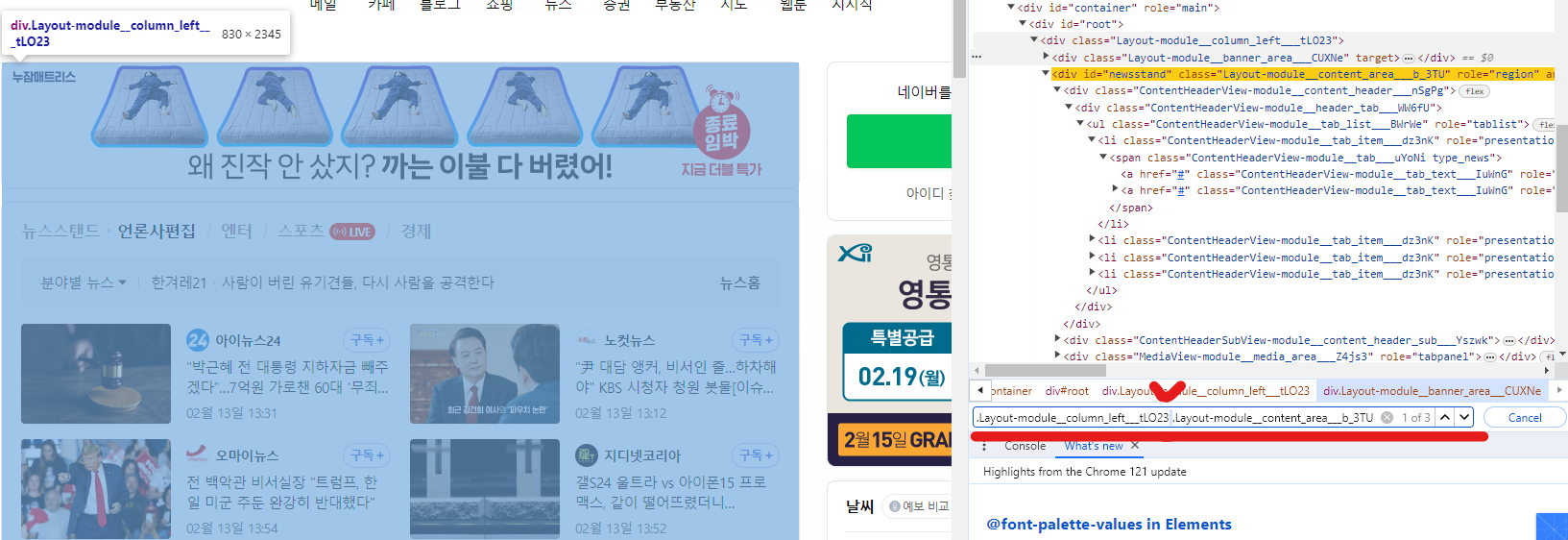
+ 기호를 통해 class 바로 옆의 형제 class를 직접 지정할 수도 있다.
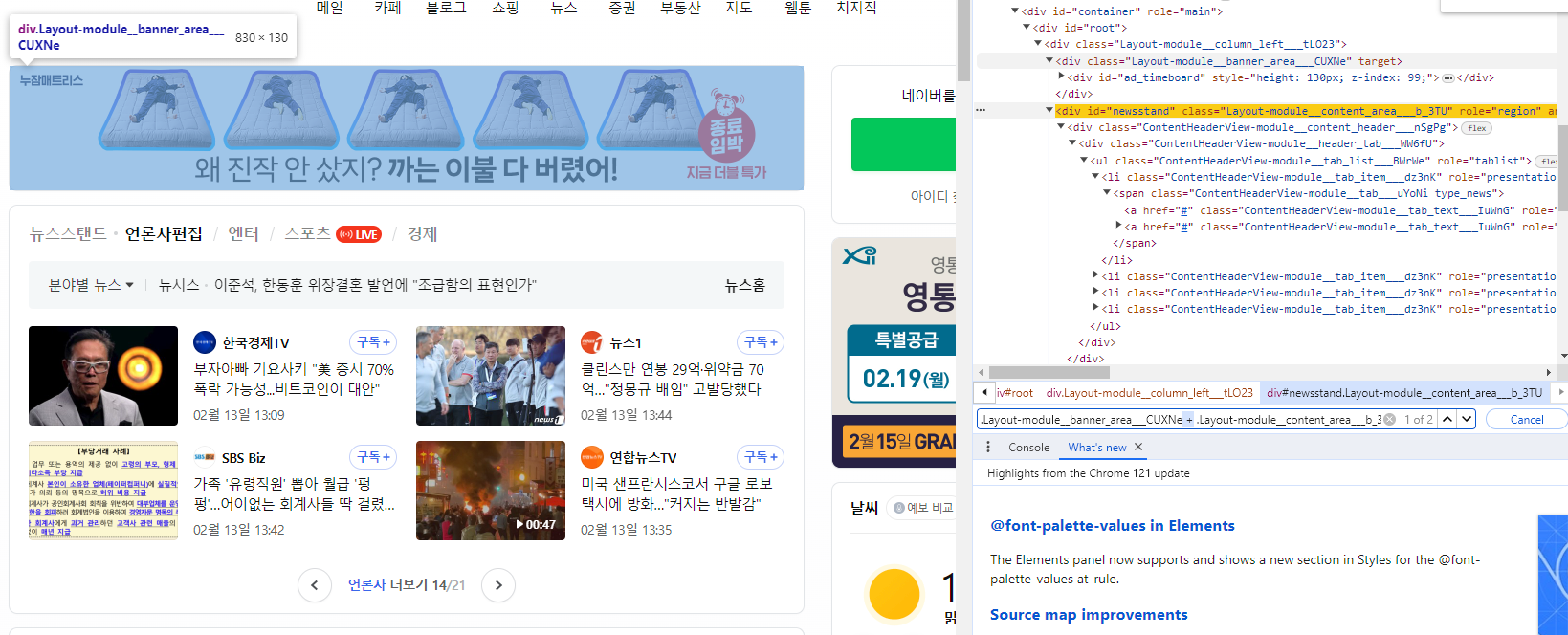
네이버에서 삼성전자 키워드로 뉴스 리스트 가져오기 예제
*requests 패키지를 사용하면 User 정보가 오류가 날 수 있다.
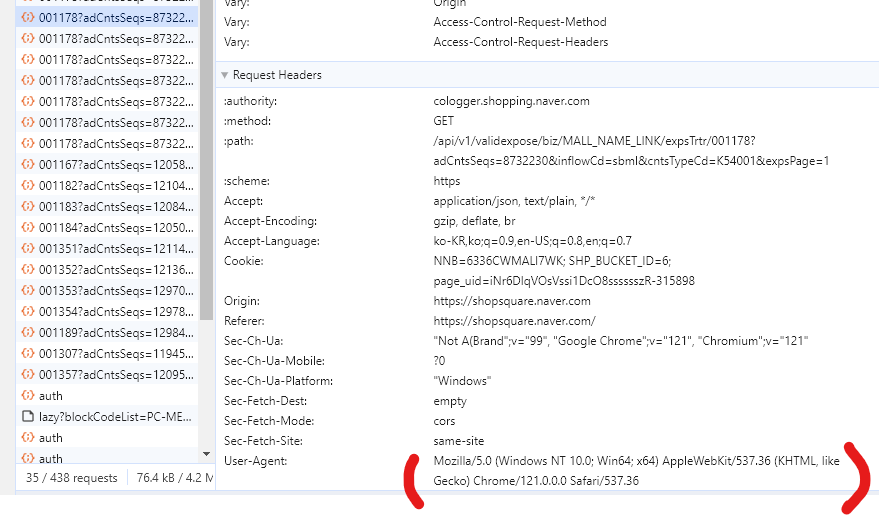
코드 맨 위에 User-Agent 정보를 넣는다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'}
response = requests.get("https://search.naver.com/search.naver", params={'where' : 'news', 'query': '삼성전자'}, headers=headers)
**참고로, Postman 에서도 같은 url로 정보가 불러와지는 것을 볼 수 있다. (마치 api불러오는 것 처럼!)
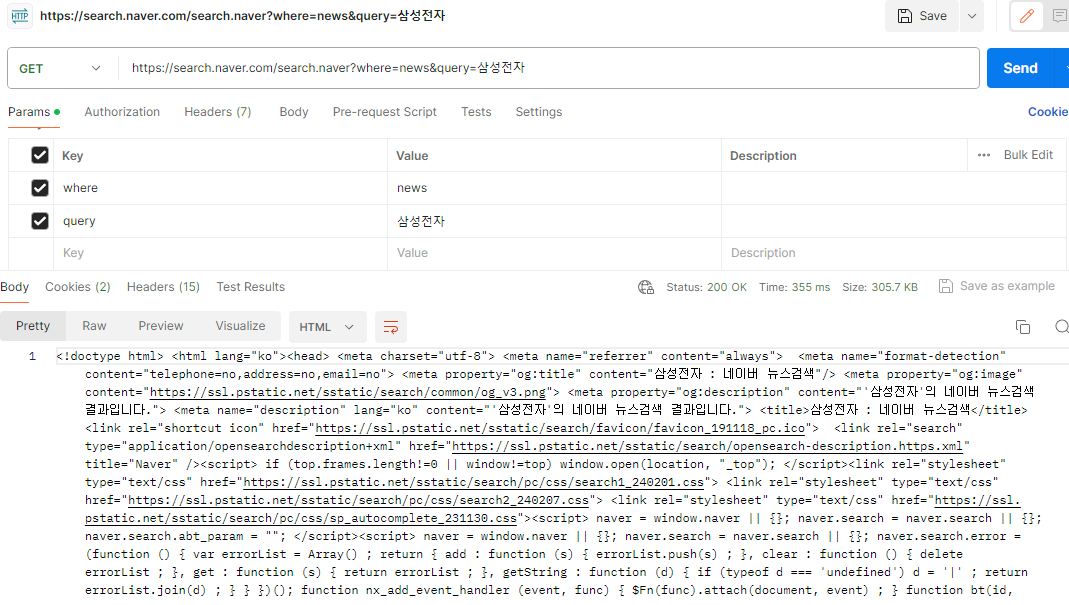
화살표 모양을 누르면 내가 원하는 부분에 해당하는 html을 볼 수 있다.
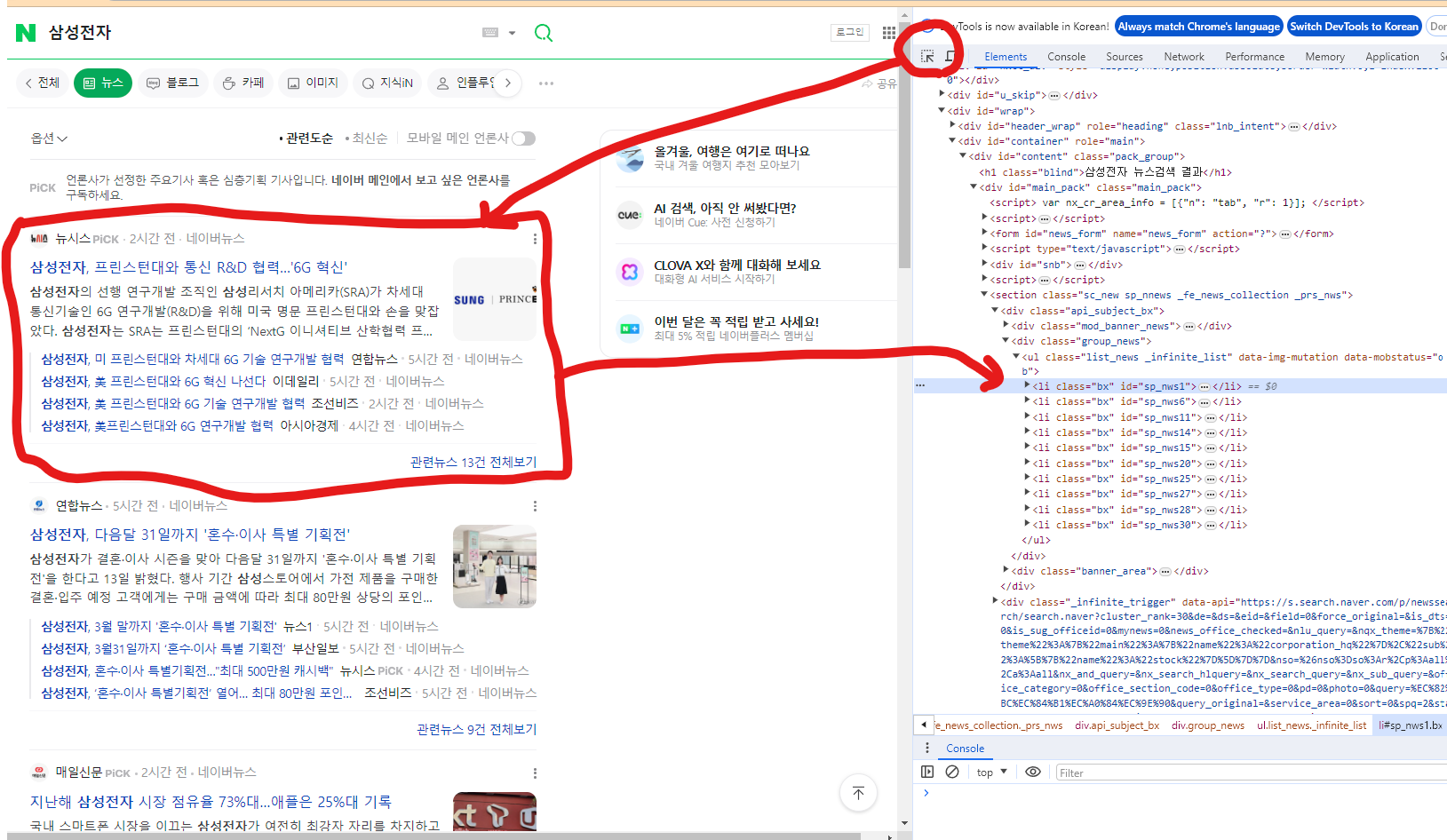
news_contents 이름의 class 10개가 기본으로 뜨는 것을 볼 수 있다.
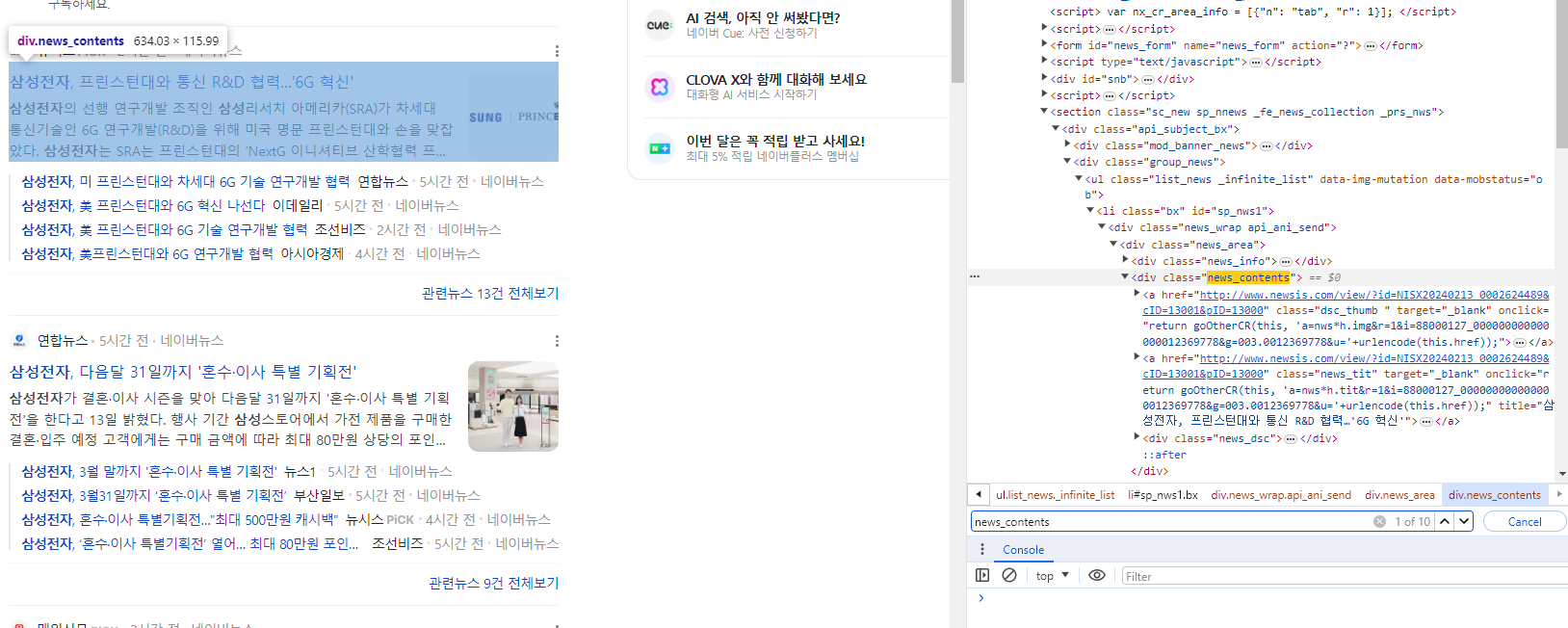
.news_contents를 가지는 class 중 [0]번째 인덱스에 해당하는 정보만 출력해본다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'}
response = requests.get("https://search.naver.com/search.naver", params={'where' : 'news', 'query': '삼성전자'}, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
news_contents = soup.select('.news_contents')
print(news_contents[0].prettify())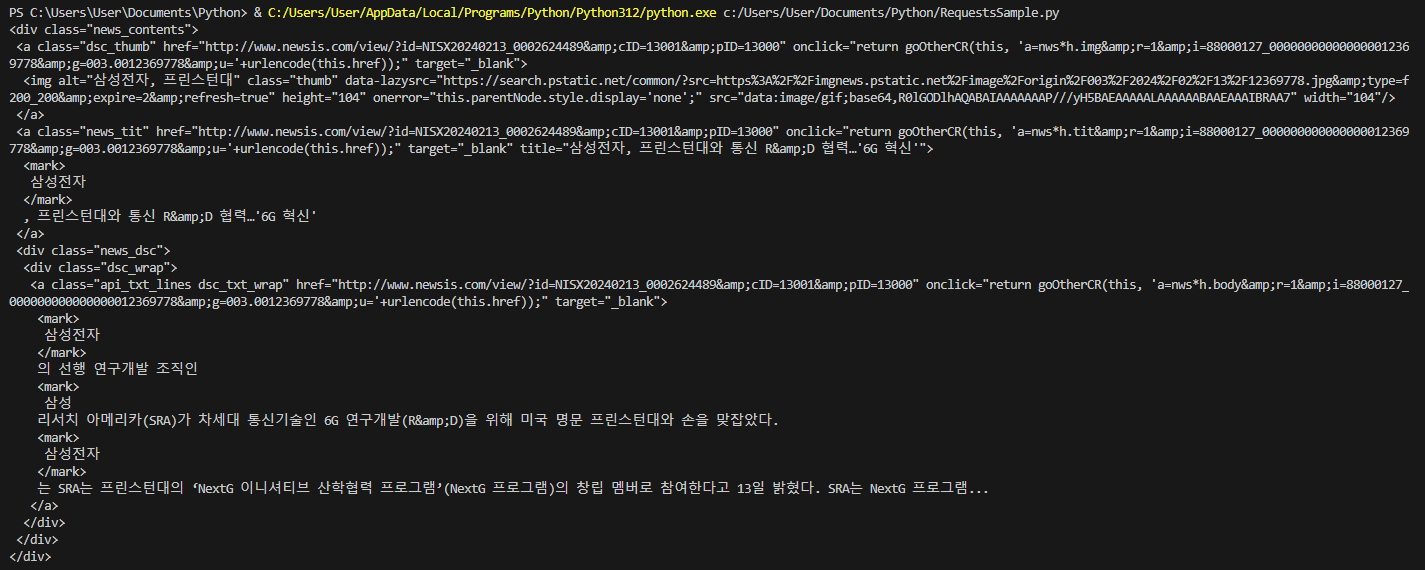
for 문을 돌려보면, 10개의 list가 모두 출력되는 것을 볼 수 있다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'}
response = requests.get("https://search.naver.com/search.naver", params={'where' : 'news', 'query': '삼성전자'}, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
news_contents = soup.select('.news_contents')
for n in news_contents:
print(n.prettify())
우리가 가져와야할 정보는 news_tit 클래스 안에 title이다.

a 태그를 가진 news_tit 클래스를 모두 가져왔다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'}
response = requests.get("https://search.naver.com/search.naver", params={'where' : 'news', 'query': '삼성전자'}, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
news_contents = soup.select('.news_contents')
for n in news_contents:
print(n.select('a.news_tit'))
#"이재용 개인배당 3237억 '부동의 1위'… 배당금 총액 1위도 삼성전자": "http://www.fnnews.com/news/202402121049497145"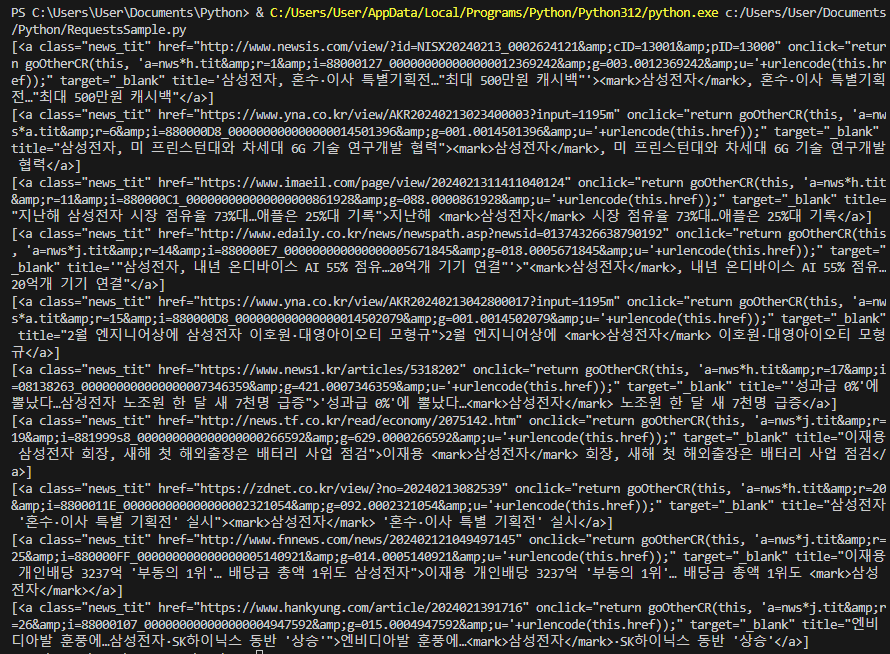
prettify() 쓰기 위해서 [0] 인덱스 사용
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'}
response = requests.get("https://search.naver.com/search.naver", params={'where' : 'news', 'query': '삼성전자'}, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
news_contents = soup.select('.news_contents')
for n in news_contents:
print(n.select('a.news_tit')[0].prettify())
#"이재용 개인배당 3237억 '부동의 1위'… 배당금 총액 1위도 삼성전자": "http://www.fnnews.com/news/202402121049497145"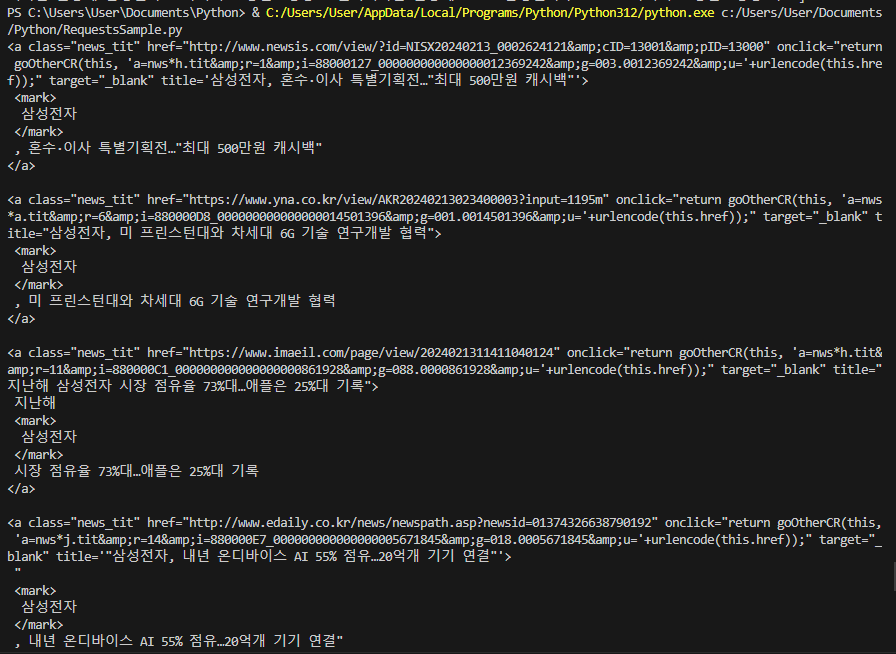
attrs에 딕셔너리 형태로 출력
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'}
response = requests.get("https://search.naver.com/search.naver", params={'where' : 'news', 'query': '삼성전자'}, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
news_contents = soup.select('.news_contents')
for n in news_contents:
print(n.select('a.news_tit')[0].attrs['title'])
#"이재용 개인배당 3237억 '부동의 1위'… 배당금 총액 1위도 삼성전자": "http://www.fnnews.com/news/202402121049497145"
제목: 링크 형태로 출력하기
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'}
response = requests.get("https://search.naver.com/search.naver", params={'where' : 'news', 'query': '삼성전자'}, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
news_contents = soup.select('.news_contents')
for n in news_contents:
print(n.select('a.news_tit')[0].attrs['title'] + ': ', n.select('a.news_tit')[0].attrs['href'])
#"이재용 개인배당 3237억 '부동의 1위'… 배당금 총액 1위도 삼성전자": "http://www.fnnews.com/news/202402121049497145"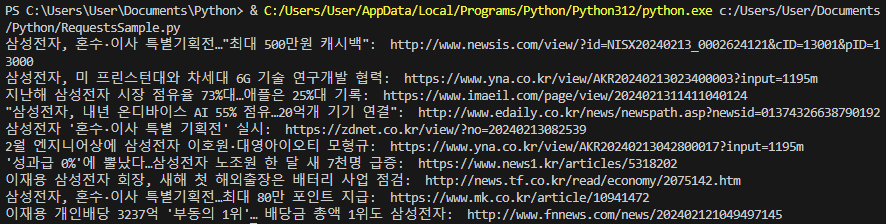
조금 더 분석하자면, 네이버 뉴스를 계속 스크롤 다운 하면 새 뉴스가 뜨는데, 여기도 URL이 있기 때문에 새로 스크롤링 할 때 새로운 URL을 가지고 많은 뉴스 리스트를 가져올 수 있다.
네이버 연관 검색어 텍스트로 가져오기 실습
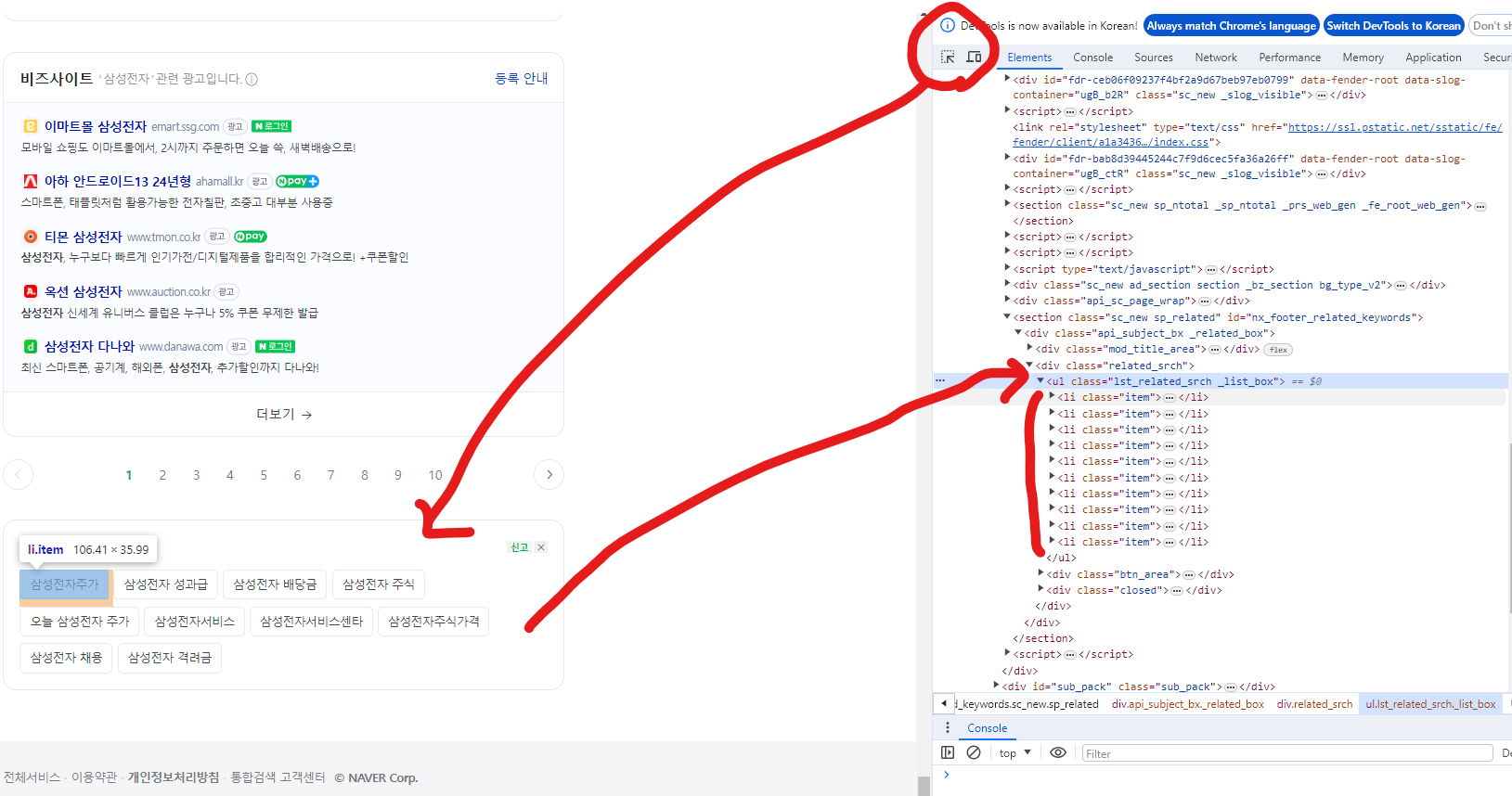
네이버 검색 맨 아래를 보면 연관검색어 리스트가 있고, 개발자 툴에서 화살표 모양을 클릭하고 해당 구역을 누르면 HTML에서 해당 구역 리스트를 볼 수 있다.
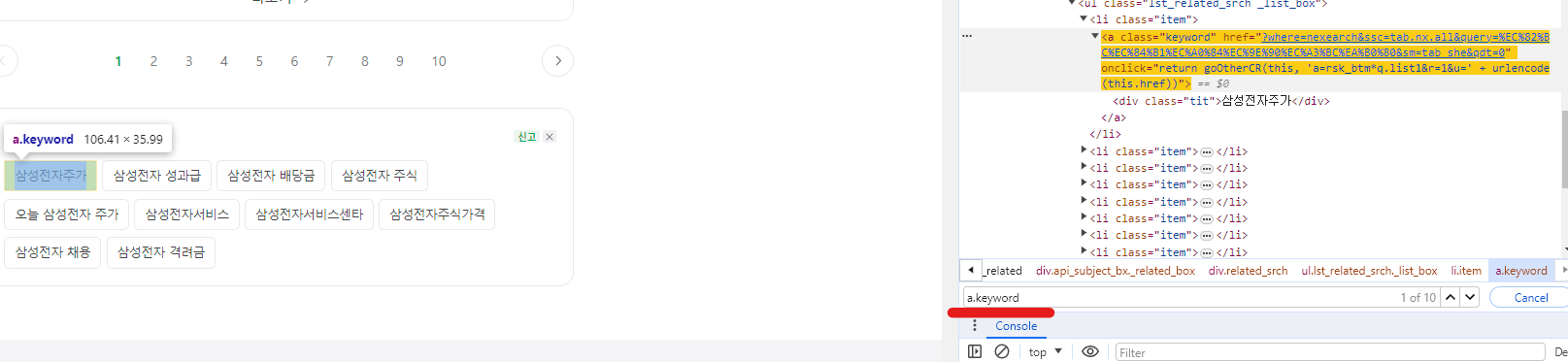
a.keyword로 검색하면 바로 연관 검색어로 검색이 되고 이를 이용해서 텍스트를 가져오면 될 것 같다.
일단 연관 키워드 하나 정보 가져오는 것은 성공하였다.
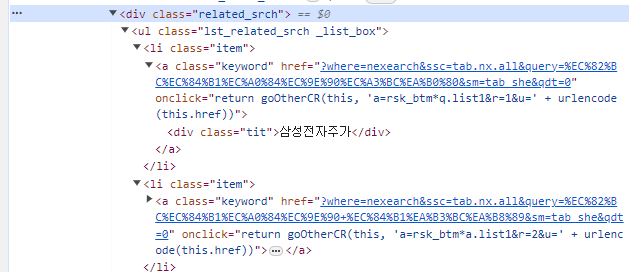
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'}
response = requests.get("https://search.naver.com/search.naver", params={'where' : 'news', 'query': '삼성전자'}, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
related_texts = soup.select('.related_srch')
for n in related_texts:
print(n.select('a.keyword')[0])
아래의 코드로 연관 검색어 리스트를 불러올 수 있다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'}
response = requests.get("https://search.naver.com/search.naver", params={'where' : 'news', 'query': '삼성전자'}, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
li = soup.select('.lst_related_srch._list_box > li.item > .keyword > .tit')
for n in li:
print(n.get_text())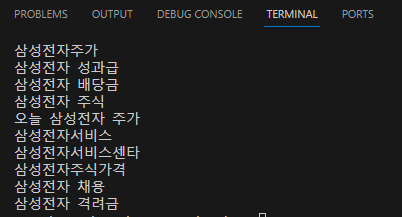
네이버 뉴스 상세페이지 조회하기 예제
이전 예제에서 코드를 살짝 바꾸면 구현 가능할 것으로 보인다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'}
response = requests.get("https://search.naver.com/search.naver", params={'where' : 'news', 'query': '삼성전자'}, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
news_contents = soup.select('.news_contents')
news_link = news_contents[0].select('a.news_tit')[0].attrs['href']
news_detail_res = requests.get(news_link)
soup_news = BeautifulSoup(news_detail_res.content, 'html.parser')
print(soup_news.prettify())
print('link: ', news_link)
네이버 주가 정보 가져오기
https://finance.naver.com/item/sise.nhn?code=005930
네이버페이 증권
국내 해외 증시 지수, 시장지표, 뉴스, 증권사 리서치 등 제공
finance.naver.com
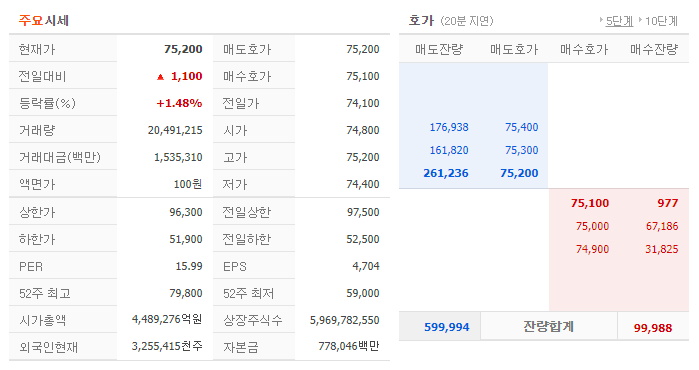
주요시세 데이터를 전부 가져와보자.
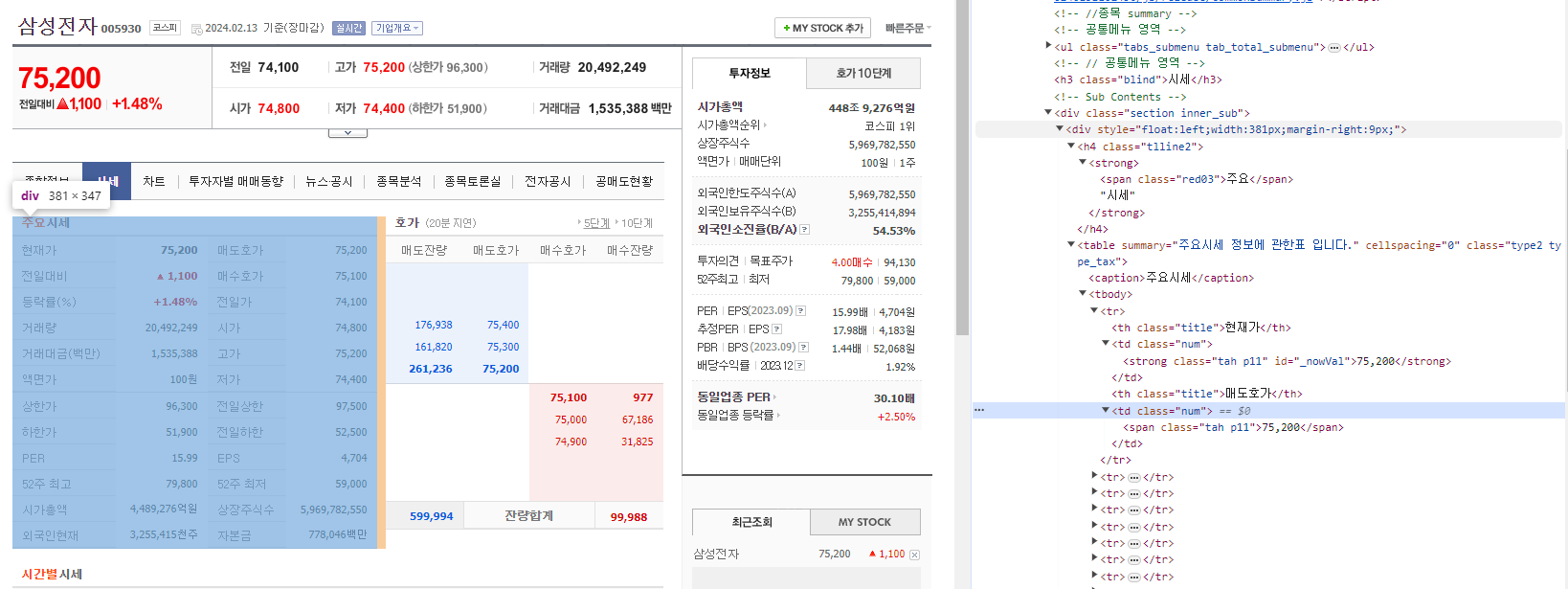
해당 부분의 HTML을 보면 구조가 보인다.
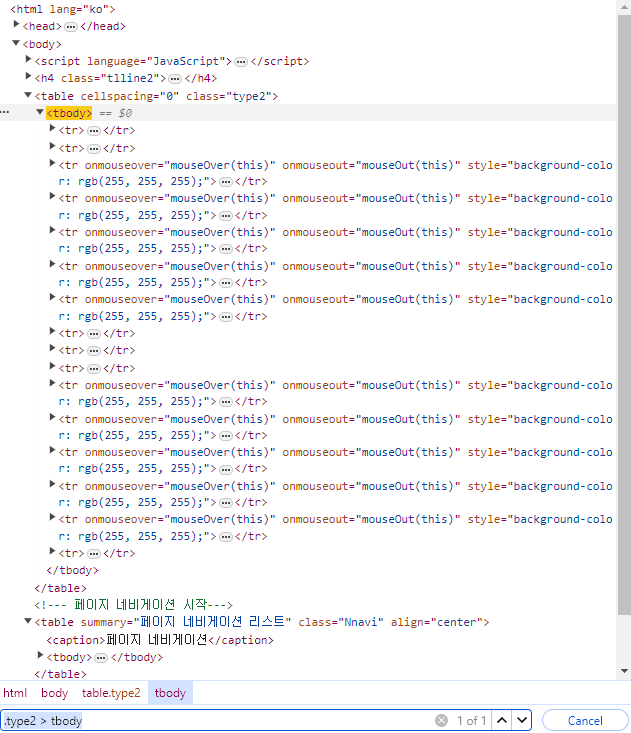
.type2.type_tax에 자식이 tbody인건 하나밖에 없다. 이렇게 접근한다.
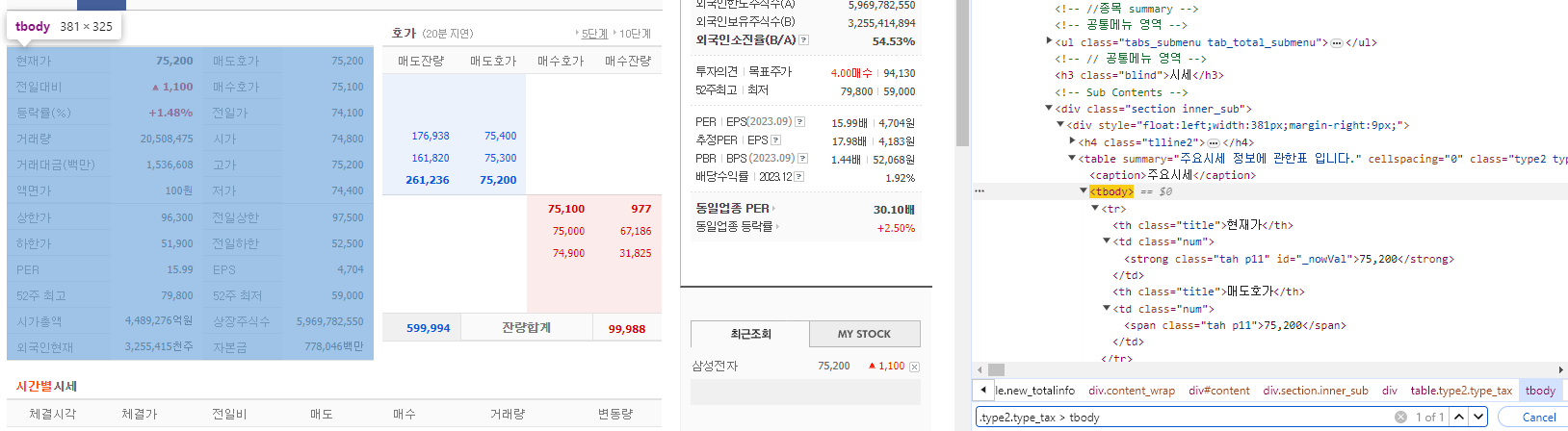
tbody 아래에 tr, td에 접근해야 숫자 텍스트까지 닿을 수 있다.
완성된 파이썬 코드는 아래와 같다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'}
response = requests.get("https://finance.naver.com/item/sise.nhn?", params={'code' : '005930'}, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
table = soup.select('.type2.type_tax > tbody')[0]
tr_list = table.select('tr')
for tr in tr_list:
th_list = tr.select('tr > th')
td_list = tr.select('tr > td') #[<td>2134</td>, <td>243</td>]
for idx, th in enumerate(th_list):
td = ''
if td_list[idx].get_text().find('상승') == -1:
td = td_list[idx].get_text().strip() #strip은 문자열의 좌우 공백을 제거해준다.
else:
td = '+' + td_list[idx].select('.tah.p11.red01')[0].get_text().strip()
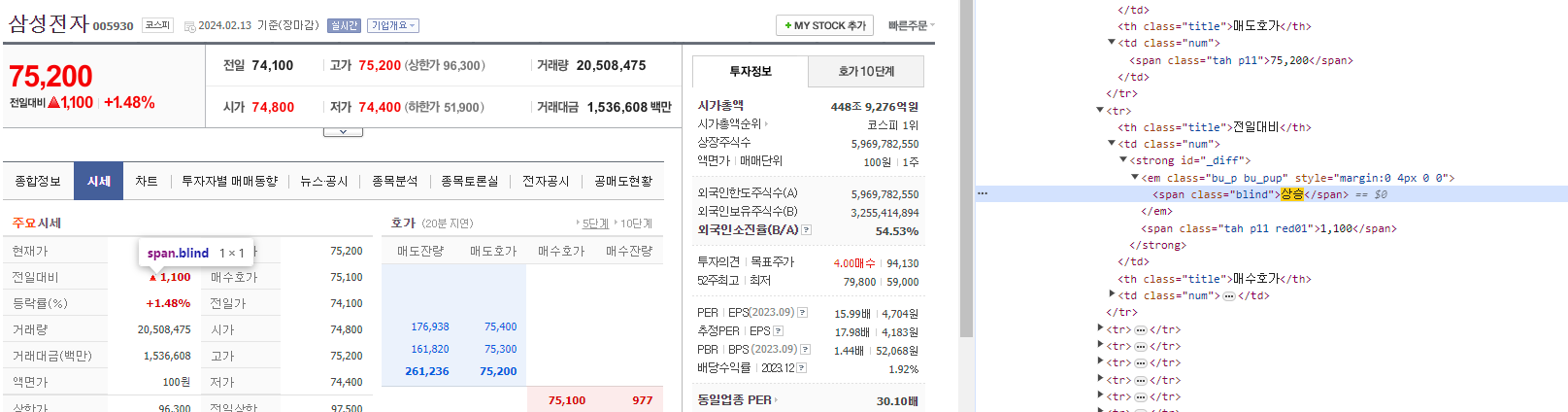
print(th.get_text().strip() + ':', td)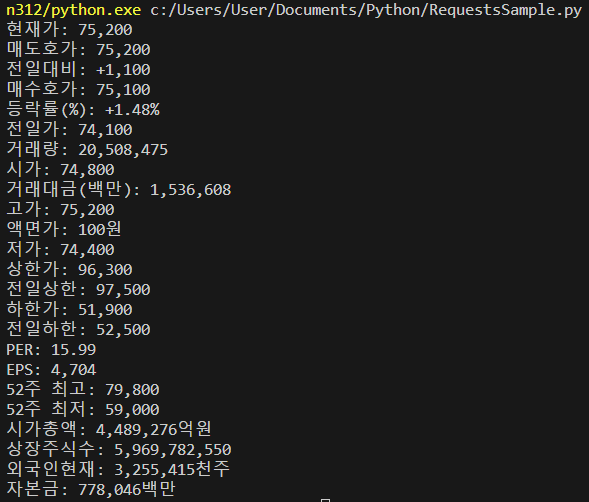
코드에 '상승'을 따로 처리한 이유는 HTML에서 '상승'이 숨어있기 때문이다. 전일대비: 상승 <-> 1,100 에서 상승을 지우고 상승과 숫자 사이의 공백까지 없애기 위해서 find로 '상승'이 없으면 if문, 있으면 else문으로 돌아간다.
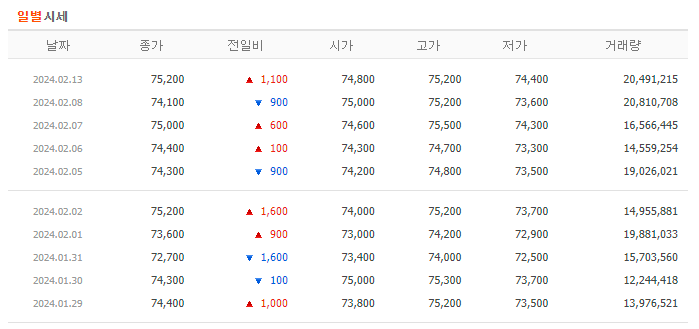
아래에 있는 일별시세 가져오기
*iframe: 브라우저는 Frame 단위로 이루어져있고, 일별시세는 html안에 html이 또 들어있는 형식이다.
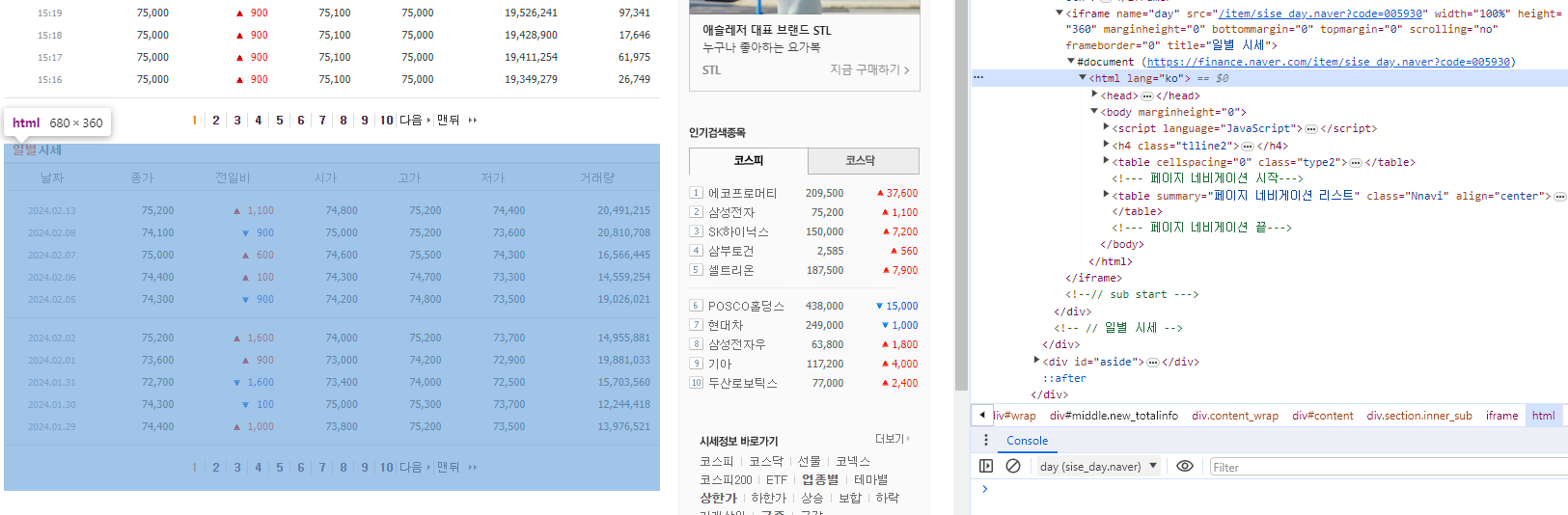
iframe의 링크를 한 번 더 타고 가면 표 형식의 페이지가 열린다.
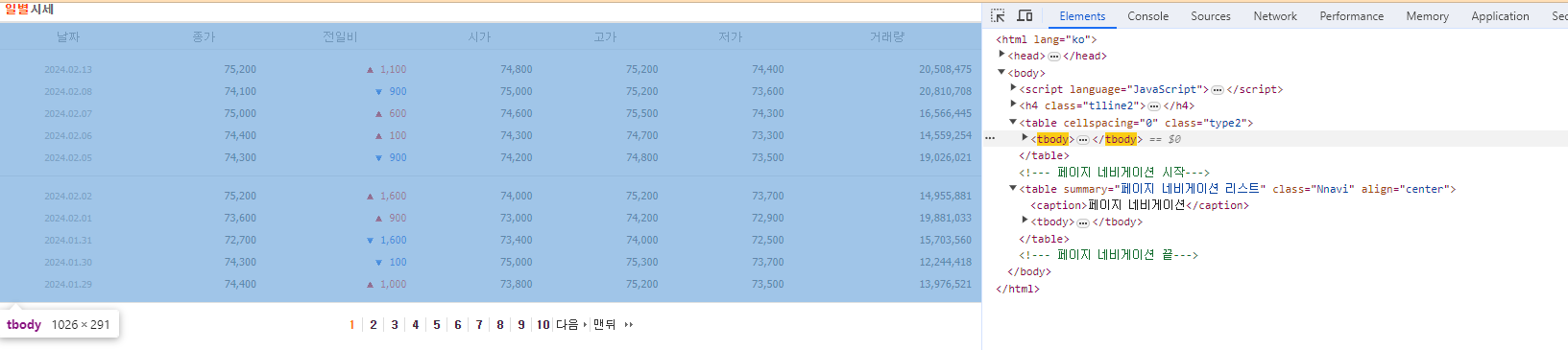
tbody가 페이지에서 두 번 쓰이기 때문에 .type2 > tbody로 내가 필요한 tbody를 직접 지정한다.
'SKKU DT' 카테고리의 다른 글
| [SKKU DT] 72일차 -웹 스크래핑(웹 크롤링)(3) Selenium 인스타그램 크롤링, 유튜브 크롤링 / MySQL 데이터베이스 (2) | 2024.02.15 |
|---|---|
| [SKKU DT] 71일차 -웹 스크래핑(웹 크롤링)(2) 시각화, Selenium (0) | 2024.02.14 |
| [SKKU DT] 69일차 -유니티 Shader Graph(셰이더 그래프), Particle System(파티클 시스템) 정리, 예제 (0) | 2024.02.07 |
| [SKKU DT] 68일차 -유니티 Rest API 활용하기(뉴스 기사, 주식 정보), Shader Graph(셰이더 그래프) (1) | 2024.02.06 |
| [SKKU DT] 67일차 -유니티 Rest API 활용하기(날씨, 정보, 사진) (1) | 2024.02.05 |