2024. 2. 15. 16:32ㆍSKKU DT
인스타그램 크롤링
아래는 완성된 인스타그램 크롤링 파이썬 코드이다.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
from dotenv import load_dotenv # pip install python-dotenv
import os
from selenium.common.exceptions import NoSuchElementException
import pandas as pd
selector = {
'id_input':'._aa4b._add6._ac4d._ap35',
'first_post': '._ac7v.xzboxd6.xras4av.xgc1b0m div a ._aagu > ._aagv + ._aagw',
'next_btn': '._aaqg._aaqh > ._abl-',
'cover': '._ac7v.xzboxd6.xras4av.xgc1b0m div ._aagu ._aagv img',
'text': 'h1._ap3a._aaco._aacu._aacx._aad7._aade',
'like': 'span a span .html-span.xdj266r.x11i5rnm.xat24cr.x1mh8g0r.xexx8yu.x4uap5.x18d9i69.xkhd6sd.x1hl2dhg.x16tdsg8.x1vvkbs',
'date': '._aaqe'
}
brands = ['nike', 'chanelofficial', 'hermes', 'adidas', 'gucci']
load_dotenv(verbose=True)
INSTAGRAM_ID = os.getenv('INSTAGRAM_ID')
INSTAGRAM_PASSWORD = os.getenv('INSTAGRAM_PASSWORD')
options = webdriver.ChromeOptions()
options.add_argument('User-Agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36')
driver = webdriver.Chrome()
driver.get('https://instagram.com')
driver.implicitly_wait(10)
driver.maximize_window()
def click_nxt():
next_btn = driver.find_element(By.CSS_SELECTOR, selector['next_btn'])
next_btn.click()
driver.implicitly_wait(10)
# 인스타그램 로그인하기
el = driver.find_elements(By.CSS_SELECTOR, selector['id_input']) # ID input태그 선택하기
el[0].send_keys(INSTAGRAM_ID)
el[1].send_keys(INSTAGRAM_PASSWORD)
el[1].send_keys(Keys.ENTER)
time.sleep(10)
text = []
image = []
like = []
date = []
data = {
'text': text,
'image': image,
'like': like,
'date': date
}
# 의류브랜드 데이터 수집
for b in brands:
driver.get(f'https://instagram.com/{b}/')
driver.implicitly_wait(10)
images = []
for i in range(10):
cover = driver.find_elements(By.CSS_SELECTOR, selector['cover'])[i]
images.append(cover.get_attribute('src'))
image = [*image, *images]
post = driver.find_elements(By.CSS_SELECTOR, selector['first_post'])[0]
post.click()
driver.implicitly_wait(10)
for i in range(10):
try:
text.append(driver.find_element(By.CSS_SELECTOR, selector['text']).text)
except NoSuchElementException: #본문이 없는 게시물 예외 처리
text.append('')
count = driver.find_element(By.CSS_SELECTOR, selector['like']).text
if count == '':
time.sleep(1) #카운트가 들어오지 않을 경우 1초 있다가 다시 불러오기
like.append(driver.find_element(By.CSS_SELECTOR, selector['like']).text)
date.append(driver.find_element(By.CSS_SELECTOR, selector['date']).get_attribute('title'))
if i < 9:
next_btn = driver.find_element(By.CSS_SELECTOR, selector['next_btn'])
next_btn.click()
driver.implicitly_wait(10)
data.update({'image': image})
df = pd.DataFrame(data)
df.set_index(keys=['date'], inplace=True, drop=True)
df.to_excel('./instagram.xlsx')
print(df)
time.sleep(10)
날짜, 본문, 좋아요 수를 저장하고 엑셀로도 볼 수 있다.
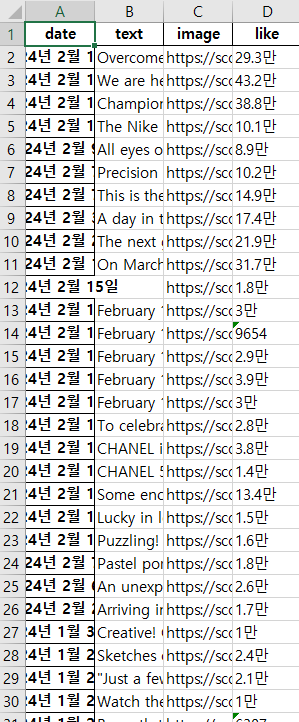
아래는 크롤링 되는 모습이다. 매우 빠르게 페이지가 넘어가는 것을 볼 수 있다.

유튜브 크롤링 하기
-동영상 다운로드
-댓글 목록 가져오기
-댓글 감성 분석하기(nltk 자연어 처리 툴킷 라이브러리, textblob 텍스트 감정 분석)
pip install pytube 설치하기
pip install textblob 설치하기
감정은 polarity가 1에 가까울 수록 긍정적, -1에 가까울 수록 부정적
subjectivity가 높을 수록 주관적(0~1)
from pytube import YouTube
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import pandas as pd
from textblob import TextBlob
url = 'https://www.youtube.com/watch?v=uJMCNJP2ipI'
yt = YouTube(url) #데드풀 티저 영상
#유튜브 영상 다운로드
stream = yt.streams.get_highest_resolution()
stream.download(output_path='./deadpool')
options = webdriver.ChromeOptions()
options.add_argument('User-Agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)')
driver = webdriver.Chrome()
driver.get(url)
driver.implicitly_wait(10)
time.sleep(5)
driver.maximize_window()
comment = []
polarity = []
subjectivity = []
data = {
'comment': comment,
'polarity': polarity,
'subjectivity': subjectivity
}
comments = driver.find_elements(By.CSS_SELECTOR, '#content-text')
for c in comments:
blob = TextBlob(c.text.strip())
sentiment = blob.sentiment
comment.append(c.text.strip())
polarity.append(sentiment.polarity)
subjectivity.append(sentiment.subjectivity)
#data
df = pd.DataFrame(data, index=None)
print(df)
영상도 다운받아졌다!!

MySQL
https://dev.mysql.com/downloads/mysql/
MySQL :: Download MySQL Community Server
Select Version: 8.3.0 Innovation 8.0.36 5.7.44 Select Operating System: Select Operating System… Microsoft Windows Ubuntu Linux Debian Linux SUSE Linux Enterprise Server Red Hat Enterprise Linux / Oracle Linux Fedora Linux - Generic Oracle Solaris macOS
dev.mysql.com
8.0.36버전 MySQL을 다운로드 한다.
MySQL 사이트 접속, 중간에 Go to Download Page 버튼을 누른다.
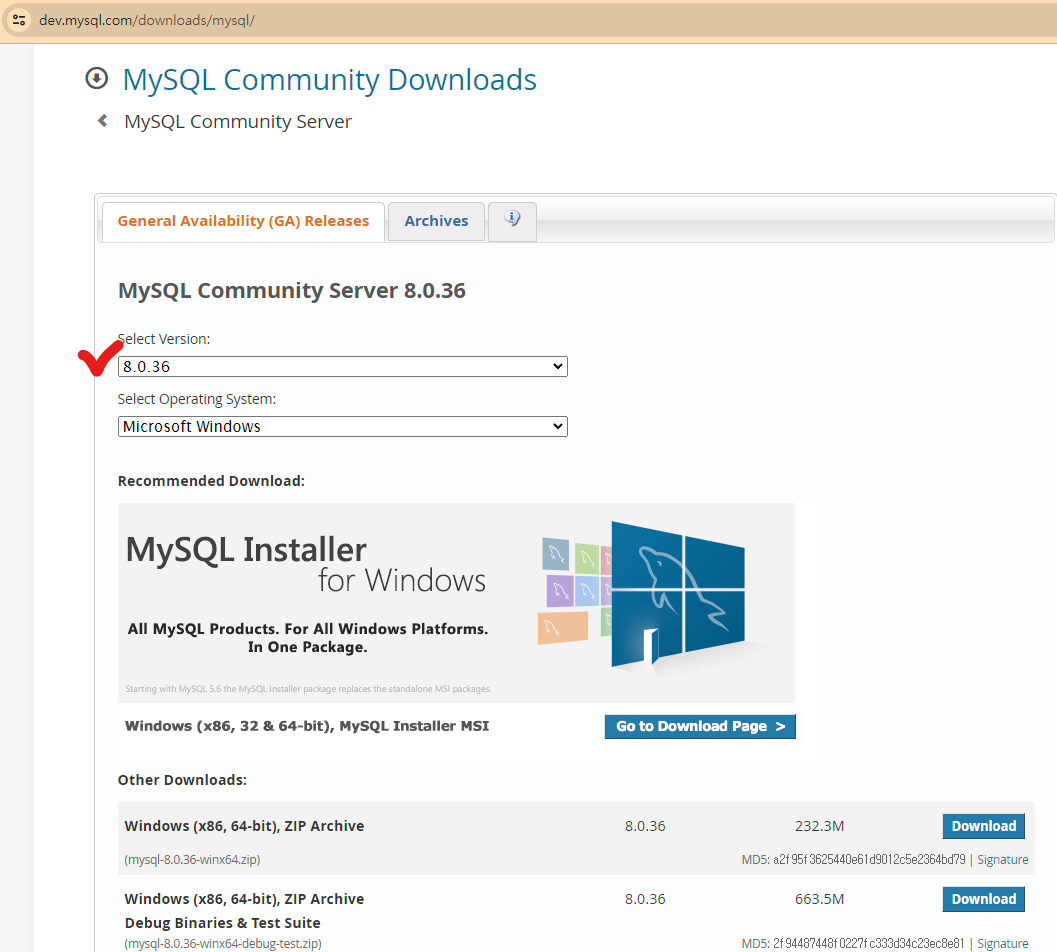
아래쪽에 더 큰 용량의 파일 다운로드

아래에 No thanks, just start my download 클릭해서 다운로드 받는다.
Full 선택,
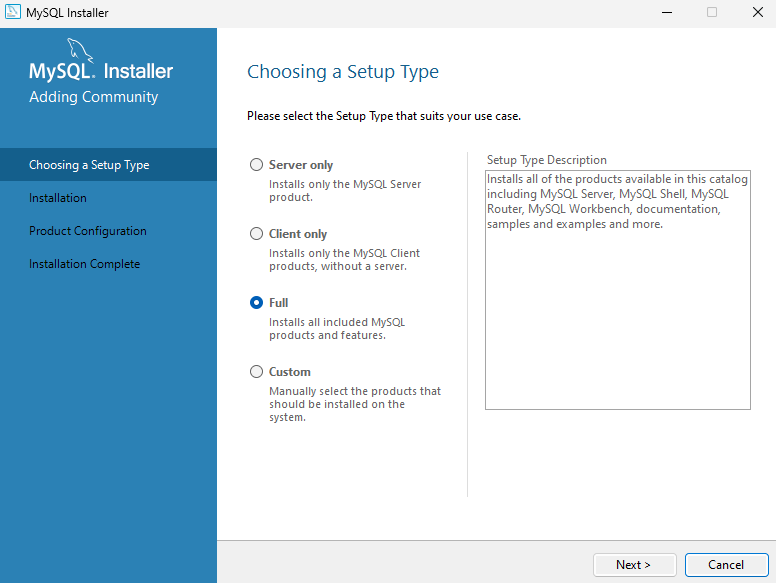
중간에 루트 패스워드 설정, 이후 쭉 Next 하면 된다.

진행하다가, 패스워드 부분은 바로 위에서 만들었던 패스워드를 입력한다.

잘 설치 되었다면 MySQL Workbench 화면이 뜬다.

내 계정 네모 박스를 눌러 로그인한다.

접속하면 아래와 같은 창을 볼 수 있다.

마우스 오른쪽 버튼 눌러 새 스키마 만들기

설정은 밑에 그림을 참조한다.

테이블 새로 만들기


NN 체크 - 무조건 값이 있어야 한다.
UQ 체크 - 같은 값이 들어갈 수 없다.
UN 체크 - 음수가 들어갈 수 없다.
AI 체크 - 값을 따로 만들어주지 않아도 1부터 번호가 매겨진다.
설정을 다 했으면 Apply 눌러서 테이블을 생성한다.
text 테이블 오른쪽에 세 개의 아이콘 중에 가장 오른쪽을 누르면 테이블을 볼 수 있다.

가운데 버튼을 누르면 아까와 같은 설정창을 볼 수 있고 수정도 가능하다. updatedAt을 추가했다.
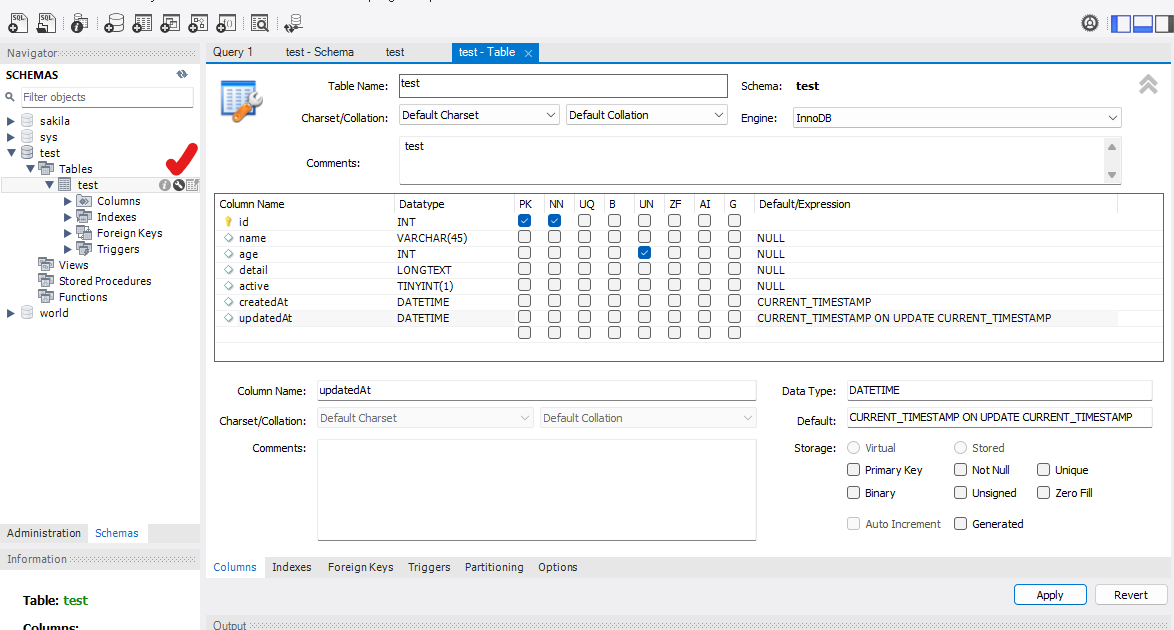
*Join과 Foreign Key에 대한 설명은 다음을 참조하면 된다.

CRUD
-Create, Read, Update, Delete
INSERT INTO users (name, email) VALUES (%s, %s);
SELECT * FROM users WHERE email = ‘euginy89@gmail.com’ OR email in (‘이름’, ‘Name’);
UPDATE users SET email = %s WHERE name = %s;
DELETE FROM users WHERE name = %s;
위의 CRUD를 바탕으로 쿼리를 작성한다.
AI 체크

쿼리를 작성하고 번개모양 아이콘을 누르거나 Ctrl + Enter를 하면 적용된다.
INSERT INTO test.test (name, age, detail, active) VALUES ('이름', 10, '', 1);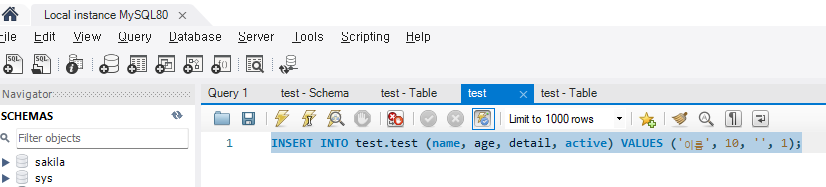
첫 번째 줄에 정보가 추가된 것을 볼 수 있다.


계속 추가도 가능하다.

불러오는 건 SELECT로 가능하다. 전체 불러오기
SELECT * FROM test.test;
WHERE 조건으로 불러오기
SELECT * FROM test.test WHERE name = '홍길동';
IN 뒤에 괄호 안에 하나라도 부합하면 불러와진다.
SELECT * FROM test.test WHERE name IN ('홍길동', '박길동');
Update로 수정하기
UPDATE test.test SET name = '박길동' WHERE id = 2;
두 번째 줄 이름이 박길동으로 바뀐 것을 볼 수 있다.
세 번째 줄도 추가하고 원하는 대로 바꿀 수 있다.
UPDATE test.test SET detail = '안녕하세요' WHERE id = 3;
DELETE로 삭제하기
DELETE FROM test.test WHERE id = 1
삭제된 것을 볼 수 있다.
LIKE
LIKE는 와일드카드로 '김'이 들어가는 부분은 다 검색이 된다.
하지만 성능 저하 이슈로 잘 쓰지는 않는다.
SELECT * FROM test.test WHERE name LIKE '김%'
ORDER BY
SELECT * FROM test.test WHERE name IN ('김길동', '박길동') ORDER BY id DESC
오름차순과 내림차순으로 정렬시킬 수 있다.
SELECT * FROM test.test WHERE name IN ('김길동', '박길동') ORDER BY id DESC LIMIT 1
LIMIT을 사용하면 몇 개를 가져오는 지를 정할 수 있다.
자식 테이블 만들기
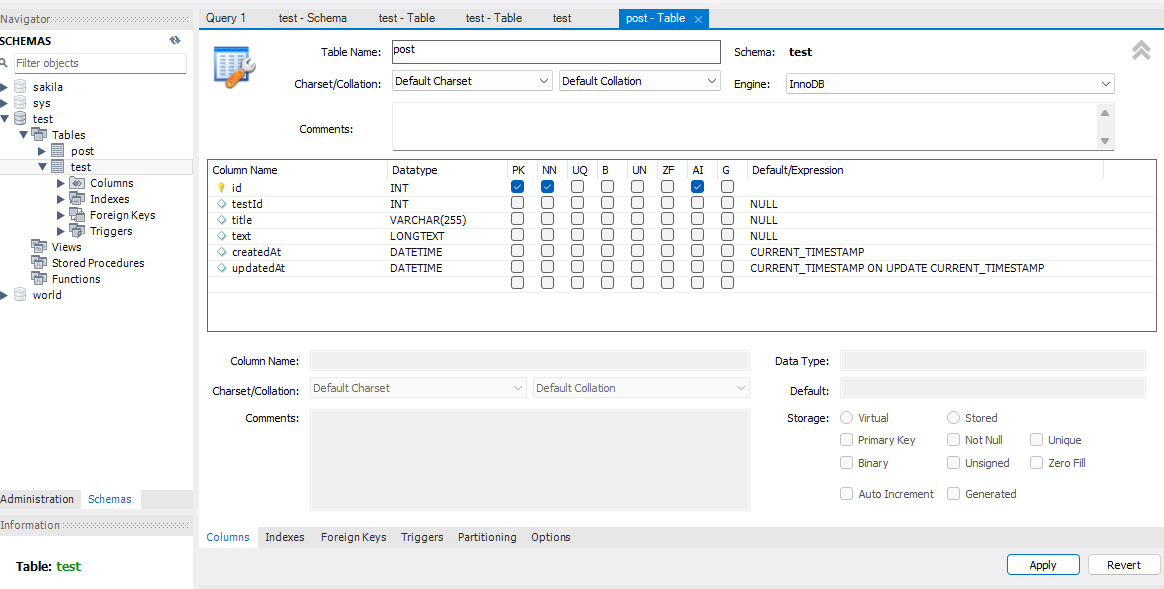
Insert 구문 이용해서 자식 테이블에 데이터 넣기
INSERT INTO test.post (title, text) VALUE ('게시물 제목', '게시물 본문')
testId도 추가해서 많이 넣어놨다. 이 테이블을 test.test 테이블과 JOIN으로 합칠 것이다.
INSERT INTO test.post (testId, title, text) VALUE (2, '게시물 제목-2', '게시물 본문-2')
JOIN

JOIN을 실행하면 아래처럼 합쳐지게 된다.
SELECT * FROM test.post JOIN test.test ON post.testId = test.id;
testId 3만 가져온다.
SELECT * FROM test.post JOIN test.test ON post.testId = test.id WHERE testId = 3;
'김길동'의 데이터만 가져온다.
SELECT * FROM test.post JOIN test.test ON post.testId = test.id WHERE name = '김길동';
post 테이블의 Foreign Key 수정
post 테이블에서 아래 Foreign Keys 탭에서 아래와 같이 설정하고 Apply 한다.

*CASCADE: 부모의 정보가 삭제되면 자식 테이블의 정보도 자동으로 따라서 삭제 가능
Reverse Engineer로 시각화 하기

Reverse Engineer... 메뉴 누르고, 비밀번호 입력하고, 위에서 만들었던 test 데이터베이스 체크하고 계속 Next 누르면 관계도가 나온다.

MySQL을 Python과 연동하기
터미널에서 pip install PyMySQL 설치
Python 코드 작성
import pymysql
connection = pymysql.connect(host='localhost',
user='root',
password='비밀번호 입력',
database='test',
port=3306,
cursorclass=pymysql.cursors.DictCursor) #cursor는 데이터베이스를 탐색하는 역할, 딕셔너리 타입으로 반환
try:
with connection.cursor() as cursor: #탐색을 해주는 cursor 생성
sql = '''
CREATE TABLE
IF NOT EXISTS users (id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
email VARCHAR(255))
'''#줄바꿈 해도 이어지는 작은따옴표 3개
cursor.execute(sql)
#데이터 저장 create
sql = '''
INSERT INTO users (name, email) VALUES (%s, %s)
'''
cursor.execute(sql, ('홍길동', 'ghdrlfehd@gamil.com')) #두 번째 인자로 %s에 들어갈 데이터 삽입. 튜플 형태 혹은 리스트 형태로 넣을 수 있음
#변경사항 저장
connection.commit()
#다시 cursor 생성 후 데이터 조회 read
with connection.cursor() as cursor:
sql = 'SELECT * FROM users'
cursor.execute(sql)
result = cursor.fetchall()
for row in result:
print(row)
finally:
connection.close()
데이터가 잘 생성되었다.

env 파일을 만들어서 보안을 유지할 수도 있다.
.env 파일은 아래와 같고,
DB_HOST=localhost
DB_USERNAME=root
DB_PASSWORD=비밀번호
DB_DATABASE=test
DB_PORT=3306
코드는 아래처럼 dotenv를 써서 표현할 수 있다.
import pymysql
from dotenv import load_dotenv
import os
load_dotenv(verbose=True)
DB_HOST=os.getenv('DB_HOST')
DB_USERNAME=os.getenv('DB_USERNAME')
DB_PASSWORD=os.getenv('DB_PASSWORD')
DB_DATABASE=os.getenv('DB_DATABASE')
DB_PORT=os.getenv('DB_PORT')
connection = pymysql.connect(host=DB_HOST,
user=DB_USERNAME,
password=DB_PASSWORD,
database=DB_DATABASE,
port=int(DB_PORT),
cursorclass=pymysql.cursors.DictCursor) #cursor는 데이터베이스를 탐색하는 역할, 딕셔너리 타입으로 반환
try:
with connection.cursor() as cursor: #탐색을 해주는 cursor 생성
sql = '''
CREATE TABLE
IF NOT EXISTS users (id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
email VARCHAR(255))
'''#줄바꿈 해도 이어지는 작은따옴표 3개
#cursor.execute(sql)
#데이터 저장 create
sql = '''
INSERT INTO users (name, email) VALUES (%s, %s)
'''
#cursor.execute(sql, ('홍길동', 'ghdrlfehd@gamil.com')) #두 번째 인자로 %s에 들어갈 데이터 삽입. 튜플 형태 혹은 리스트 형태로 넣을 수 있음
#변경사항 저장
#connection.commit()
#다시 cursor 생성 후 데이터 조회 read
with connection.cursor() as cursor:
sql = 'SELECT * FROM test JOIN post ON test.id = post.testId'
cursor.execute(sql)
result = cursor.fetchall()
for row in result:
print(row)
finally:
connection.close()
JOIN한 전체 데이터를 가져온 모습이다.
하지만 너무 많고 지저분해서 몇 개만 가져오도록 수정한다.
sql = 'SELECT name, age, title, text FROM test JOIN post ON test.id = post.testId'
데이터 키 값을 바꿔주기도 가능
sql = 'SELECT name AS author, age, title, text FROM test JOIN post ON test.id = post.testId'
특정 이름만 가져오기 가능
sql = 'SELECT name AS author, age, title, text FROM test JOIN post ON test.id = post.testId WHERE name = %s'
cursor.execute(sql, '김길동')
아이디와 패스워드를 확인하는 식으로도 사용할 수 있다.
sql = 'SELECT name AS author, age, title, text FROM test JOIN post ON test.id = post.testId WHERE password = %s AND id = %s'
cursor.execute(sql, '김길동', myid)
**지금은 많이 막혔지만 sql injection이라는 공격 방법이 있다.
Selenium 실습 -데이터를 데이터베이스에 저장하기
-brand 테이블 만들기
-contents 테이블 만들고 brand 테이블의 id를 외래키로 지정하기
-brand 별로 컨텐츠를 select 올 수 있게 함수 만들기
ex) getByBrand('nike') 라면,
-> SELECT id FROM brand WHERE name IS 'nike';
가져온 id로 contents 테이블 검색
-> SELECT * FROM contents WHERE brandId = <brandId>;
컨텐츠 반환
이전에 인스타 크롤링 코드 위쪽에 데이터베이스 파이썬 코드의 일부를 추가한다.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
from dotenv import load_dotenv # pip install python-dotenv
import os
from selenium.common.exceptions import NoSuchElementException
import pandas as pd
import pymysql
load_dotenv(verbose=True)
DB_HOST=os.getenv('DB_HOST')
DB_USERNAME=os.getenv('DB_USERNAME')
DB_PASSWORD=os.getenv('DB_PASSWORD')
DB_DATABASE=os.getenv('DB_DATABASE')
DB_PORT=os.getenv('DB_PORT')
INSTAGRAM_ID = os.getenv('INSTAGRAM_ID')
INSTAGRAM_PASSWORD = os.getenv('INSTAGRAM_PASSWORD')
connection = pymysql.connect(host=DB_HOST,
user=DB_USERNAME,
password=DB_PASSWORD,
database=DB_DATABASE,
port=int(DB_PORT),
cursorclass=pymysql.cursors.DictCursor)
selector = {
'id_input':'._aa4b._add6._ac4d._ap35',
'first_post': '._ac7v.xzboxd6.xras4av.xgc1b0m div a ._aagu > ._aagv + ._aagw',
'next_btn': '._aaqg._aaqh > ._abl-',
'cover': '._ac7v.xzboxd6.xras4av.xgc1b0m div ._aagu ._aagv img',
'text': 'h1._ap3a._aaco._aacu._aacx._aad7._aade',
'like': 'span a span .html-span.xdj266r.x11i5rnm.xat24cr.x1mh8g0r.xexx8yu.x4uap5.x18d9i69.xkhd6sd.x1hl2dhg.x16tdsg8.x1vvkbs',
'date': '._aaqe'
}
brands = ['nike', 'chanelofficial', 'hermes', 'adidas', 'gucci']
options = webdriver.ChromeOptions()
options.add_argument('User-Agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36')
driver = webdriver.Chrome()
driver.get('https://instagram.com')
driver.implicitly_wait(10)
driver.maximize_window()
def click_nxt():
next_btn = driver.find_element(By.CSS_SELECTOR, selector['next_btn'])
next_btn.click()
driver.implicitly_wait(10)
# 인스타그램 로그인하기
el = driver.find_elements(By.CSS_SELECTOR, selector['id_input']) # ID input태그 선택하기
el[0].send_keys(INSTAGRAM_ID)
el[1].send_keys(INSTAGRAM_PASSWORD)
el[1].send_keys(Keys.ENTER)
time.sleep(10)
text = []
image = []
like = []
date = []
data = {
'text': text,
'image': image,
'like': like,
'date': date
}
# 의류브랜드 데이터 수집
for b in brands:
driver.get(f'https://instagram.com/{b}/')
driver.implicitly_wait(10)
images = []
for i in range(10):
cover = driver.find_elements(By.CSS_SELECTOR, selector['cover'])[i]
images.append(cover.get_attribute('src'))
image = [*image, *images]
post = driver.find_elements(By.CSS_SELECTOR, selector['first_post'])[0]
post.click()
driver.implicitly_wait(10)
for i in range(10):
try:
text.append(driver.find_element(By.CSS_SELECTOR, selector['text']).text)
except NoSuchElementException: #본문이 없는 게시물 예외 처리
text.append('')
count = driver.find_element(By.CSS_SELECTOR, selector['like']).text
if count == '':
time.sleep(1)
like.append(driver.find_element(By.CSS_SELECTOR, selector['like']).text)
date.append(driver.find_element(By.CSS_SELECTOR, selector['date']).get_attribute('title'))
if i < 9:
next_btn = driver.find_element(By.CSS_SELECTOR, selector['next_btn'])
next_btn.click()
driver.implicitly_wait(10)
data.update({'image': image})
df = pd.DataFrame(data)
df.set_index(keys=['date'], inplace=True, drop=True)
df.to_excel('./instagram.xlsx')
print(df)
time.sleep(10)
기존 데이터시트에 E, F열에 brandId와 Id를 추가할 것이다.

따로 파이썬 스크립트로 brand 테이블 만들기
import pymysql
from dotenv import load_dotenv
import os
load_dotenv(verbose=True)
DB_HOST=os.getenv('DB_HOST')
DB_USERNAME=os.getenv('DB_USERNAME')
DB_PASSWORD=os.getenv('DB_PASSWORD')
DB_DATABASE=os.getenv('DB_DATABASE')
DB_PORT=os.getenv('DB_PORT')
connection = pymysql.connect(host=DB_HOST,
user=DB_USERNAME,
password=DB_PASSWORD,
database=DB_DATABASE,
port=int(DB_PORT),
cursorclass=pymysql.cursors.DictCursor) #cursor는 데이터베이스를 탐색하는 역할, 딕셔너리 타입으로 반환
try:
with connection.cursor() as cursor: #탐색을 해주는 cursor 생성
sql = '''
CREATE TABLE
IF NOT EXISTS brand (id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255))
'''#줄바꿈 해도 이어지는 작은따옴표 3개
cursor.execute(sql)
#변경사항 저장
connection.commit()
finally:
connection.close()
다음 시간에 이어서...
'SKKU DT' 카테고리의 다른 글
| [SKKU DT] 74일차 -C#, 유니티 팁 정리 (0) | 2024.02.19 |
|---|---|
| [SKKU DT] 73일차 -MySQL 데이터베이스, FastAPI (1) | 2024.02.16 |
| [SKKU DT] 71일차 -웹 스크래핑(웹 크롤링)(2) 시각화, Selenium (0) | 2024.02.14 |
| [SKKU DT] 70일차 -웹 스크래핑(웹 크롤링), 파이썬 (1) | 2024.02.13 |
| [SKKU DT] 69일차 -유니티 Shader Graph(셰이더 그래프), Particle System(파티클 시스템) 정리, 예제 (0) | 2024.02.07 |